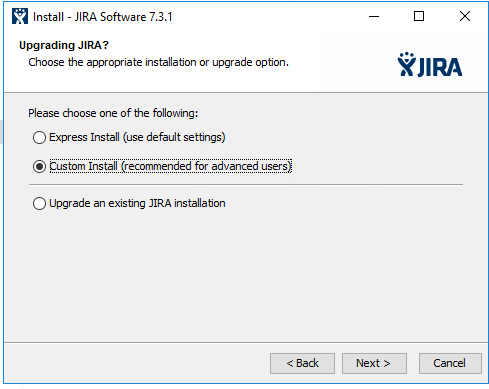
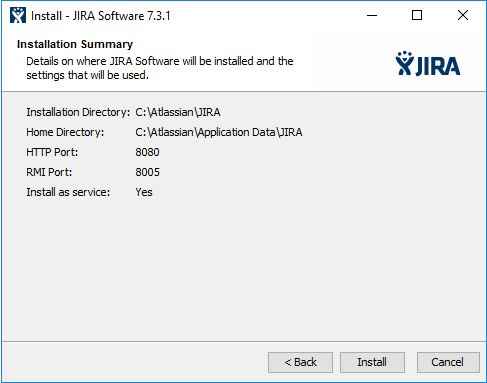
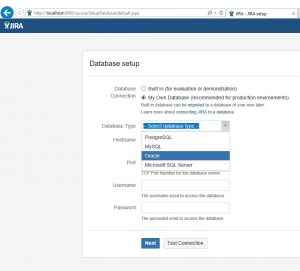
Рассмотрим установку Docker на примере CentOS, одно из наиболее используемое ПО в практике DevOPS. При работе с CentOS у вас есть выбор: использовать последнюю версию из upstream или версию, собранную проектом CentOS с дополнениями Red Hat. Описание изменений доступно на странице.
В основном это обратное портирование исправлений из новых версий upstream и изменения, предложенные разработчиками Red Hat, но пока не принятые в основной код. Наиболее заметным различием на момент написания статьи было то, что в новых версиях сервис docker был разделен на три части: демон docker, containerd и runc. Red Hat пока не считает, что это изменение стабильно, и поставляет монолитный исполнимый файл версии 1.10. Настройки репозитория для установки upstream-версии, как и инструкции для инсталляции в других дистрибутивах и ОС, приведены в руководстве по инсталляции на официальном сайте Docker . В частности, настройки для репозитория CentOS 7:
# cat /etc/yum.repos.d/docker.repo [dockerrepo] name=Docker Repository baseurl=https://yum.dockerproject.org/repo/main/centos/7 enabled=1 gpgcheck=1 gpgkey=https://yum.dockerproject.org/gpg
Устанавливаем необходимые пакеты и запускаем и включаем сервис:
# yum install -y docker-engine # systemctl start docker.service # systemctl enable docker.service
Проверяем статус сервиса:
# systemctl status docker.service
Также можно посмотреть системную информацию о Docker и окружении:
# docker info
При запуске аналогичной команды в случае установки Docker из репозиториев CentOS увидите незначительные отличия, обусловленные использованием более старой версии программного обеспечения. Из вывода docker info можем узнать, что в качестве драйвера для хранения данных используется Device Mapper, а в качестве хранилища – файл в /var/lib/docker/:
# ls -lh /var/lib/docker/devicemapper/devicemapper/data -rw-------. 1 root root 100G Dec 27 12:00 /var/lib/docker/devicemapper/devicemapper/data
Опции запуска демона, как это обычно бывает в CentOS, хранятся в /etc/sysconfig/. В данном случае имя файла docker. Соответствующая строчка /etc/sysconfig/docker, описывающая опции:
OPTIONS='--selinux-enabled --log-driver=journald'
Для того чтобы пользоваться командой docker без применения sudo, необходимо добавить пользователя, с правами которого вы работаете, в группу docker:
# usermod -aG docker andrey
Если бы вы запустили команду docker не пользователем root и не пользователем, входящим в группу docker, вы бы увидели подобную ошибку:
$ docker search mysql Warning: failed to get default registry endpoint from daemon (Cannot connect to the Docker daemon. Is the docker daemon running on this host?). Using system default: https://index.docker.io/v1/ Cannot connect to the Docker daemon. Is the docker daemon running on this host?
Обратите внимание, что фактически включение пользователя в группу docker равносильно включению этого пользователя в группу root. У разработчиков RHEL/CentOS несколько иной подход к безопасности демона Docker, чем у разработчиков самого Docker из upstream. Подробнее о подходе Red Hat написано в статье разработчика дистрибутива RHEL Дэна Уолша.
Если же вы хотите «стандартное» поведение Docker, установленного из репозиториев CentOS (т.е. описанное
в официальной документации), то необходимо создать группу docker и добавить в опции запуска демона:
OPTIONS='--selinux-enabled --log-driver=journald --group=docker'
После чего рестартуем сервис и проверяем, что файл сокета docker принадлежит группе docker, а не root:
# ls -l /var/run/docker.sock srw-rw----. 1 root docker 0 Dec 27 13:32 /var/run/docker.sock
Поиск образов и тэги Попробуем найти контейнер на Docker Hub.
$ docker search haproxy NAME DESCRIPTION haproxy HAProxy - The Reliable, High Perf... eeacms/haproxy HAProxy Docker image with docker ... million12/haproxy Fully customisable HAProxy load b... STARS OFFICIAL AUTOMATED 607 [OK] 17 [OK] 14 [OK] ...
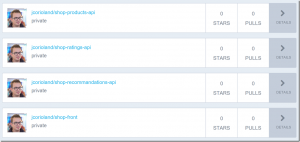
В данном выводе мы получили список ряда образов HA Proxy. Самый верхний элемент списка – это HA Proxy
из официального репозитория. Такие образы отличаются тем, что в имени отсутствует символ «/», отделяющий имя репозитория пользователя от имени самого контейнера. В примере за официальным показаны два образа haproxy из открытых репозиториев пользователей eeacms и million12.
Образы, подобные двум нижним, можете создать сами, зарегистрировавшись на Docker Hub. Официальные же поддерживаются специальной командой, спонсируемой Docker, Inc. Особенности официального репозитория:
- Это рекомендованные к использованию образы, созданные с учетом лучших рекомендаций и практик.
- Они представляют собой базовые образы, которые могут стать отправной точкой для более тонкой настройки. Например, базовые образы Ubuntu, CentOS или библиотек и сред разработки.
- Содержат последние версии программного обеспечения с устраненными уязвимостями.
- Это официальный канал распространения продуктов.
Чтобы искать только официальные образы, можете использовать опцию –filter “is-official=true” команды docker search.
Число звезд в выводе команды docker search соответствует популярности образа. Это аналог кнопки Like
в социальных сетях или закладок для других пользователей. Automated означает, что образ собирается автоматически из специального сценария Dockerfile средствами Docker Hub. Обычно следует отдавать предпочтение автоматически собираемым образам вследствие того, что его содержимое может быть проверено знакомством с соответствующим файлом Dockerfile.
Скачаем официальный образ HA Proxy:
$ docker pull haproxy Using default tag: latest
Обратите внимание, что в выводе была указана загрузка образа с тэгом latest. Использование тэгов позволяет
обращаться к конкретной версии. Помимо самого образа haproxy, был скачен базовый образ и все промежуточные, от которых зависит скачиваемый. Чтобы скачать конкретную версию, используем:
$ docker pull haproxy:1.5
Полное имя образа может выглядеть следующим образом:
[URI репозитория][имя пользователя]имя образа[:тэг]
Просмотреть список скаченных образов можно командойdocker images:
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/haproxy latest c0a3eb080707 13 days ago 138 MB
Команда docker images с опцией -q вернет только идентификаторы образов, что может быть полезным для использования идентификаторов в качестве входных значений для другой команды. Например, команды docker rmi, которая удаляет образ. Для того чтобы удалить все имеющиеся в локальном кэше образы, можно воспользоваться такой командой:
$ docker rmi $(docker images -q)
Установка, настройка и поддержка Docker контейнеров, обращайтесь office@itfb.com.ua