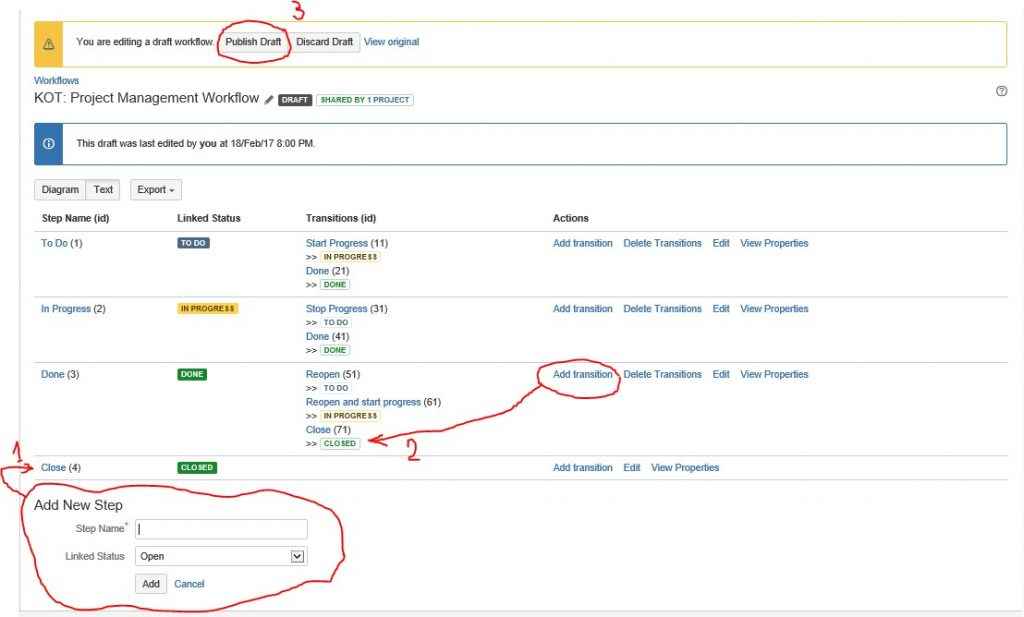
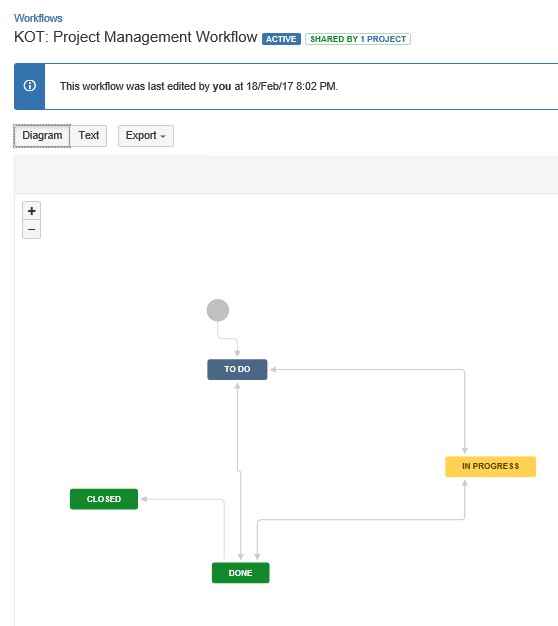
Hyper-V появился в Windows 2008 значительно расширив функционал Windows сервер. Еще бы – средство виртуализации, использующее аппаратные ресурсы, да еще и бесплатное (если Вы конечно купили windows сервер для прочих нужд) смогло со временем составить достойную конкуренцию лидеру систем виртуализации VMware.
На данный момент в Windows Server 2016 работает версия 10тая версия Hyper-V
И за эти 8 лет появилась масса полезных функций и улучшений. Наиболее значимые из них, по мнению автора – это :
- Поддержка виртуальных машин Linux
- Живая миграция виртуальных машин между узлами кластера.
- Репликация виртуальных машин
- Управляемые виртуальные свичи
- Появление виртуальных машин второго поколения
- Общие VHD
- Контейнеры Windows
А также много других, не менее полезных в эксплуатации функций. О каждой из них можно рассказать много интересного. Но, чтобы было больше пользы – нужно более глубокое погружение.
Сегодня мы поговорим о работе виртуальных машин linux в среде виртуализации Hyper-V. Давайте начнем с конкретной задачи. Для автоматизации развертывания некоторой среды мне понадобилось создать несколько машин с операционной системой CentOS (была использована версия 7.3)
Был скачан требуемый дистрибутив, создана виртуальная машина второго поколения. И.. Виртуальная машина не запустилась. О чем говорит этот пример? О том, что нужно не забывать читать инструкции и Best Practices при изучении и развертывании новых продуктов. В моем случае проблема была с некорректной настройкой Secure Boot виртуальной машины. (Рисунок и пояснение Secure boot)
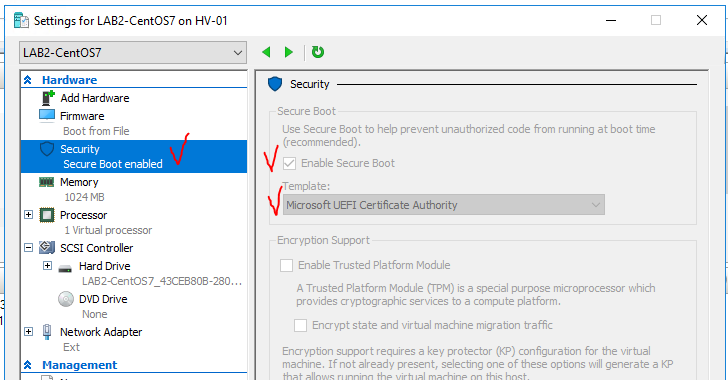
Secure boot позволяет быть уверенным, что ПО выполняющее старт ОС не скомпрометировано. Это эффективно защищает от внедрений зловредного софта в загрузчик системы.
Процесс загрузки сервера происходит следующим образом:
- Запускается аппаратная часть.
- Контроль передается BIOS, которая проверяет основные компоненты CPU, память, диски и другое оборудование.
- BIOS читает настройки загрузки и перебирает все полученные в списке устройства в поисках загрузчика в нулевом секторе.
- Если загрузчик ОС найден BIOS загрузке его в память и передает CPU для обработки.
- Загрузчик запускает систему.
Это очень упрощенная, но понятная для понимания схема. Уязвимость появляется на 4ом шаге, когда BIOS завершает свою работу. В этот момент никто не заботится о том, что будет дальше. И этим пользуются различные руткиты – это программные прокладки, обычно вредоносные, которые находятся между BIOS и операционной системой. ОС не может на них воздействовать, потому что они находятся вне зоны ее контроля, однако они могут перехватывать любые нажатия клавиш и обращения к устройствам.
С появлением UEFI ситуация изменилась. UEFI ищет не просто код в секторе 0, он ищет определенные файлы и имеет возможность выполнять некоторую их обработку, а не просто передавать их на выполнение CPU.
Secure Boot сочетает расширенные возможности загрузки и обработки с криптографическими возможностями UEFI. Ключи шифрования хранятся в прошивке. Когда UEFI запускает загрузчик ОС, он может проверить криптографическую подпись этого загрузчика ОС, если таковая имеется, ключами подписавшего, о которых он знает. Если образ был подписан доверенным ключом, UEFI разрешит его запуск. В противном случае он останавливает весь процесс загрузки и сообщает об этом.
Размножение виртуальных машин не составляет большого труда, если использовать команду PowerShell New-VM , однако здесь есть несколько подходов:
- Создать образ CentOS с «тихой» установкой.
- Установить и подготовить ОС на диске VHD и использовать диск при создании новых виртуальных машин.
Поскольку автор (в силу сложившихся обстоятельств) предпочитает платформу Windows всем остальным решениям, второй вариант был принят как основной. И следующей задачей была подготовка правильного образа-шаблона. В процессе установки ОС использовался режим Minimal Install, был создан раздел 20 ГБ, задан пароль для пользователя root и создан пользователь с правами root. Остальные настройки, в том числе конфигурация безопасности, планировалось выполнять в процессе дальнейшей конфигурации машины. Для создания шаблона было выполнено несколько шагов:
- В файл /etc/sysconfig/network добавлен следующий текст:
NETWORKING=yes
HOSTNAME=localhost.localdomain
- В файл конфигурации сетевого интерфейса /etc/sysconfig/network-scripts/ifcfg-eth0 добавлен следующий текст:
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=dhcp
TYPE=Ethernet
USERCTL=no
PEERDNS=yes
IPV6INIT=no
NM_CONTROLLED=no
Последняя строка отключает NetworkManager. Это необходимо для того, чтобы Hyper-V мог выполнить статическую настройку сетевого интерфейса.
- Выполнена команда для удаления правил udev. Эти правила приводят к появлению проблем при клонировании виртуальной машины в Hyper-V или Microsoft Azure.
sudo ln -s /dev/null /etc/udev/rules.d/75-persistent-net-generator.rules
- Очищены все текущие метаданные yum и установить все обновления с помощью команд
sudo yum clean all
sudo yum -y update
- Выполнена настройка фаервола
firewall-cmd –zone=public –add-port=22/tcp
- Выполнена установка Hyper-V tools.
sudo yum install hyperv-daemons
На последнем пункте стоит остановиться подробнее. Изначально установка тулов не планировалась из расчета, меньше ПО – меньше поломок. Но это подход не правильный. Не смотря на то, что CentOS 7 большинство фитч поддерживает без установки дополнительного ПО, на практике оказалось, что есть проблемы с созданием Snapshot’ов, которые к слову начиная с версии win 2012 называются Checkpoints. Также в моем сценарии виртуальные машины получают IP адрес по DHCP, следовательно, для дальнейшего подключения к ним нужно знать адрес, который получил виртуальный сервер. Получить его можно средствами PowerShell.
Кстати, в последней редакции Windows Hyper-V появилась функция PowerShell direct, которая позволяет управлять виртуальной машиной с Hyper-V хоста через PowerShell. Windows PowerShell Direct работает между хостовой и виртуальной машиной. Это означает, что ему не требуется сетевых настроек или настроек фаервола, он работает благодаря настройкам для удаленного подключения. Windows PowerShell Direct является альтернативой для инструментов, с помощью которых администраторы Hyper-V подключаются к виртуальной машине с Hyper-V хоста:
- Remote PowerShell и Remote Desktop
- Hyper-V Virtual Machine Connection (VMConnect)
Эти утилиты работают хорошо, но имеют свои недостатки: VMConnect и Remote Desktop сложно использовать при автоматизации. Remote PowerShell сложен в установке и обслуживании. И значимость этих недостатков растет с ростом инфраструктуры Hyper-V. Windows PowerShell Direct предоставляет мощные возможности скриптования и автоматизации вместе с простотой использования VMConnect.
Получить IP адрес машины можно используя, например, следующий набор командлетов
Get-VM |?{$_.VMName -like “LAB2-CentOS7*”} | Get-VMNetworkAdapter | ft VMName, IPAddresses, switchName -autosize
При этом получим такой вывод:
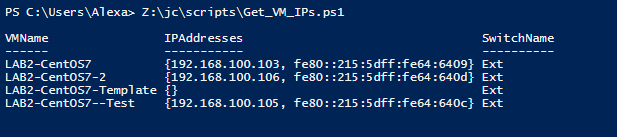
До установки тулов поле IPAdresses было пустым (как у виртуальной машины LAB2-CentOS7-Template). Нужно также отметить, что это поле заполняется не сразу после установки, а через некоторое время. Поэтому особо нетерпеливым (таким, как я J ) рекомендуется попить чаю перед тем, как начать паниковать при отсутствии ожидаемого результата.
Также я хочу отдельно остановиться на установке тулзов еще и потому, что у меня это вызвало некоторые трудности. Доверяя Microsoft, 14.03.2017 hyper-v tools были скачаны мною с официального сайта Microsoft, распакованы и установлены согласно имеющейся инструкции. Однако после перезагрузки CentOS 7.3 упрямо и безуспешно пыталась грузиться в emergencyMode. Был выполнен ряд действий, описанных в разделе инструкции Known Issues. Однако результат не был достигнут. После изучения проблемы и примеров ее решения, окрашенных, мягко скажем, нелицеприятными эпитетами в сторону Microsoft, меня посетила идея установки hyper-v tools из репозитариев CentOS. Одна единственная команда решила мою проблему.
yum install hyperv-daemons
Откровенно жаль ребят, которые писали в комментариях о том, что оказались в подобной ситуации и теперь имеют большие проблемы. Помните, тестирование решения перед внедрением в продуктивную среду никогда не бывает лишним.
Вот собственно и все. Задача по настройке Hyper-V и виртуальных машин Linux решена.
С удаленной машины я подключаюсь PowerShell скриптом к Hyper-V хосту, выполняю создание нескольких машин, копирование и подключение для каждой из них шаблонного VHD, запуск всех созданных машин и получение их IP адресов, которые потом передаются в Ansible для дальнейшей конфигурации системы. Но это уже совсем другая история.
Конечно же, многое о hyper-V осталось за кадром. Поэтому мы обязательно продолжим в будущих публикациях. А если у Вас появились вопросы – наши специалисты всегда готовы ответить на них.
Мы предоставляем услуги внедрения и поддержки систем виртуализации, office@itfb.com.ua