Дискуссия между поклонниками “железа” и облаков ведется давно. Каждый делает выбор на основании личных приоритетов: кому-то нравится адаптивный, прогрессивный функционал и относительная новизна cloud-решений, другие увлечены огромными возможностями централизации ресурсов, третьи подчеркивают такое важное преимущество, как безопасность.
И если в этих вопросах облака давно лидируют, то в плане стоимости по-прежнему возникает много разночтений. Причем основным аргументом, который выдвигают поклонники собственной аппаратной составляющей, является стоимость, рассчитанная “в массе”, без учета нюансов. Как раз эти нюансы, которые оттягивают на себя финансовый, материальный и виртуальный потенциал предприятия, мы и рассмотрим в статье. А заодно поможем вам сделать объективный вывод
Обеспечение отказоустойчивости
Cloud-проекты априори предусматривают наличие соответствующего уровня отказоустойчивости, благодаря кластеризации виртуальных серверов и автоматической резервации минимальных запасов, нужных для защиты данных. Таким образом, ресурсы могут “безболезненно” перемещаться на резервный хост для проведения на основном хосте регламентных работ, или по случаю его отказа.
Причем, такая услуга не потребует дополнительной оплаты. В стоимость виртуального диск-пространства заранее включены типы рейдов, а также резервные носители, устойчивые к множественным отказам. Если же используется своя разработка для сохранения и обработки данных, то ей будут доступны от 45 до 65 процентов “сырого” объема диска в зависимости от избранного типа RAID-массива.
Если оценивать с этой точки “железо”, то резервирование потребует вычитания нужных для него потенциалов из количества, потенциально доступного в рамках оснащения. То есть, заказчик не сможет нагрузить аппаратуру больше, чем на 80% мощностей памяти и процессора, сохранив требуемый уровень отказоустойчивости.
При такой загрузке серверы невозможно будет перезапустить на физическом уровне в случае отказа одного хоста, так как им просто не хватит возможностей. Единственный выход в таких случаях – рассчитывать, что при аварии можно будет временно приостановить некоторые сервисы, не имеющие критического значения. Однако такой вариант практически нереализуем в обычных условиях.
Пределы серверной и СХД загрузок
Специалисты знают, что во избежание колебаний производительности серверов с архитектурой х86, не стоит их загружать свыше 70-80 процентов по процессору и свыше 80-90 процентов по памяти. Особенно будут заметны такие колебания в момент запуска сервисов обслуживания (например, для резервного копирования).
Конечно, краткие всплески нагрузок качественная архитектура способна выдержать легко, но постоянные и длительные колебания во время работы грозят постепенным спадом производительности IT-структур на базе аппаратных решений.
Эта условность привела к разработке и соблюдению правил допустимой предельной утилизации оснащения, которые прописываются в соглашении в качестве обязательств провайдера.
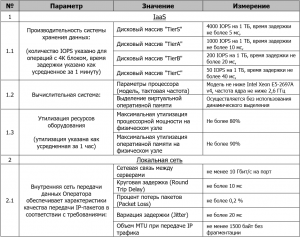
Полная утилизация доступных объемов, полученных вследствие сборки RAID-массивов, также не представляется возможной. Так как требуется резерв размером в 10% и выше от всего доступного для адресации пространства, чтобы обеспечить полноценное функционирование стораджа.
В случае хранения информации на мех.дисках и при интенсивной дисковой загрузке не стоит заполнять размеченные луны свыше 70-80%, так как это приведет к деградации производительности хранилища. Что касается all-flash стораджей, то они все еще довольно дорогостоящие. Их приобретение для многих организаций является нерентабельным, даже с учетом того, что SSD-диски не испытывают проблем, описанных выше.
Издержки из-за ограниченного масштабирования
Планирование потребляемых средств будет неполным без заложенных изначально резервов, которые обеспечат рост и масштабирование. Их размер определяется индивидуально, а здесь мы лишь упомянем общепринятые факторы влияния.
При расчетах часто отталкиваются от статистических показателей из анализа потребления за прошлые периоды. Эту динамику можно экстраполировать на будущий расчетный период, добавив еще резерв на компенсацию рисков и использование путей для реализации непредвиденных оперативных бизнес-инициатив.
Если же анализ не проводился, прогноз придется делать на основании самостоятельных предположений, исходя из планов по реализации ближайших программ и стратегической политики организации, в частности – перспектив роста и географического расширения. Вряд ли можно ожидать большой точности от такого прогноза, но лучше так, чем вообще не планировать резервы на срочные вызовы бизнеса.
Высокая конкуренция на B2C рынках обуславливает столь же высокие требования к активности и оперативности при запуске и продвижении новых продуктов или услуг. Зачастую в таких условиях уже второй по активности “игрок” получает существенные убытки вместо прибылей, а тот, кто успевает вовремя среагировать на вызовы рынка, выдерживает нужный темп – получает все.
Для поддержания оптимальной динамики бизнес-процессов нужна собственная, хорошо развитая IT-инфраструктура, которая доступна только крупным организациям, готовым инвестировать в индивидуальную экспертизу или ИТ-платформу, позволяющую эффективно распределять и перераспределять мощности между бизнес-программами.
Учитывая размеры и стоимость таких вложений, фирмы, которые вынуждены экономить, выбирают масштабирование на cloud-мощностях, гарантирующих быстрое наращивание производительности сервисного комплекса.
И хотя планирование и закладка резервов в бюджет cloud-проекта тоже применяются, но при ошибках планирования или неправильной оценке перспектив заказчик не несет значительных убытков. Облачные сервисы способны оперативно масштабироваться в соответствии с реалиями потребления. У вас попросту нет необходимости заранее покупать запасные мощности до того момента, пока они действительно не понадобятся.
В то же время, для наращивания собственной архитектуры понадобится минимум 2-3 месяца, которые уйдут на расчеты, поставки, монтаж и эксплуатационные настройки. И это при условии соблюдения принятых стандартов, с учетом налаженных процессов расчета конфигурации в определенном вендоре.
Также стоит учесть, что во многих крупных компаниях процедура закупки основных средств усложнена потребностью проводить тендерные торги по каждому наименованию. А если учесть еще и требования корпоративных регламентов, обязанность осуществлять множество согласований и привлекать к участию в тендере ряд производителей, которые являются конкурентами, то процедура наращивания пула инструментов может занять несколько месяцев, полгода или больше.
Издержки при неточной оценке объемов ключевых систем
Обычно разработка и внедрение ключевых инфосистем связана с большим количеством последующих доработок под индивидуальные требования, отладок под определенные процессы в бизнесе. В связи с этим точное изначальное планирование потребностей в обеспечении очень затруднено. Поэтому целиком приходится полагаться на опыт, профессионализм и рекомендации разработчиков.
Впрочем, они осознают ответственность в полной мере, и практически безоговорочно закладывают вероятные риски, чтобы в дальнейшем не пришлось отвечать за замедленной действие и низкую продуктивность разработки в ходе экстремальных испытаний.
Корпоративные IT-специалисты тоже заинтересованы в том, чтобы предусмотреть все риски, поскольку в противном случае рискуют своей репутацией и доходами. Таким образом, перестраховка произошла два раза – на уровне производителя и его рекомендаций, и на уровне IT-отдела, в процессе оформления заказа.
Итого, требуемые размеры резервов превышены почти втрое, вследствие чего будет простаивать более половины мощностей, в которое вложены крупные финансы. Учтем также, что принять обратно материальное обеспечение, на которое уже начислен износ, поставщик вряд ли захочет.
Все эти проблемы не знакомы организациям, которые отдали предпочтение облакам. К тому же, они помогают значительно уменьшить финансовую и техническую составляющую, если вы заинтересованы в аренде мощностей только на период интеграции проекта, поскольку позволяют выполнить масштабирование на реально развернутом ресурсе.
Правда, при этом стоит учитывать вопрос совместимости, так как при переезде на собственную технику производительность способна рухнуть без заметных причин. Но даже этот риск является незначительным по сравнению с теми, которые грозят при покупке оснащения “наугад”.
Обслуживание инфраструктуры
Регулярного сервиса требует любая техника, независимо от типа, комплектации, модели и мощности. Виртуализационные, мониторинговые, управленческие, системы бэкапа и прочие составляющие, на которые возложено поддержание стабильной, безопасной работы инфраструктуры тоже постоянно требуют внимания специалистов, то есть, периодических ремонтов, диагностики, поддержки. Профессиональные услуги таких специалистов стоят недешево, что весьма сказывается на бюджете небольшого предприятия.
С учетом масштабирования и развития, сложность рабочего стека ИТ-инфраструктуры увеличивается с каждым годом, требуя все более квалифицированных кадров и увеличения их числа.
Содержание штата ИТ-специалистов, это не только постоянные крупные расходы на оплату труда, но и обязательство управлять отделом, распределять задачи и обеспечивать новыми, для которых характерны постепенное усложнение и рост ответственности. Из-за этого небольшие фирмы просто не способны конкурировать с IT-фирмами в плане условий для удержания настоящих профессионалов.
На этом фоне желание разместить инфраструктуру в cloud даже на первый взгляд выглядит куда практичнее и дешевле. По сути, вы получаете доступ к услугам любых опытных, квалифицированных, компетентных специалистов на свой выбор (и не только в сфере ИТ), при этом не делая дополнительных вложений в содержание отдела и поддержание его функциональности.
Постоянное сотрудничество с сервис-провайдером, а также его доскональное знание ваших особенностей и нужд – все это укрепляет и оптимизирует деловые отношения, делает их еще более продуктивными, так как постоянные взаимовыгодные связи стимулируют ИТ-компанию предлагать более выгодные и комплексные решения, предоставлять приоритет при необходимости оперативно решать проблемы и новые задачи.
Конечно, даже в облаке не получится “укрыться” полностью от расходов на содержание своего ИТ-отдела, но его состав и компетенции будут более специализированными, ориентированными на тот спектр задач, которые характерны для вашего бизнеса. А глобальными вопросами инфраструктурных и пограничных сервисов будет заниматься исключительно провайдер, “разгрузив” ваш штат.
Вендорная поддержка рабочего ПО и тех.оснащения
К сожалению, нет ни одного, даже самого авторитетного производителя аппаратуры и ПО, который мог бы гарантировать 100% отсутствие брака. Самый худший (и не такой уж редкий) вариант последствий – когда отказывает не просто часть сервиса или его функционала, а вся система. Как правило, устранение проблемы, возникшей из-за производителя, требует времени даже в том случае, если вы уплатили за комплексный сервис с гарантированной, максимально оперативной поддержкой.
Причины могут быть разными: не отлажены процессы обслуживания у вендора, временные ограничения на поддержку, отсутствие нужных комплектующих, потребность в кастомных прошивках, на создание которых тратится порой несколько недель или даже месяцев. Как бы там ни было, вам это грозит потерей не только нервов, но и финансов, времени, сорванными сроками реализации задач, ответственностью (порой – материальной) перед вашим заказчиком.
В отличие от собственных, cloud-решения позволяют и эти риски делегировать провайдеру, который справится с ними намного быстрее и эффективнее – не только в силу опыта, но и из-за наработанных связей.
Возведение и содержание серверной
Чтобы достичь хотя бы надлежащего уровня безопасности и надежности своей серверной, придется инвестировать в ее постройку минимум 100 тыс. долларов, и это без учета всего оборудования. Но даже в этом случае любой специализированный дата-центр будет более функциональным и надежным по ряду причин.
Основная из них – потребность следить за репутацией, так как cloud-провайдер обслуживает одновременно множество клиентов, среди которых – крупные мировые компании. Даже непродолжительный отказ или недоступность cloud-сервиса по любой причине, в том числе – форс-мажорной, сильно снижает авторитет провайдера и гарантирует отток определенной части заказчиков.
Если вы решите создать собственную серверную по минимальным стандартам, для обеспечения первоочередных нужд оснащения и с приемлемыми условиями его эксплуатации, капитальные затраты все равно лягут большим грузом на ваш бюджет.
Среди таких затрат – проектирование и постройка помещения, прокладка инженерных линий, подключение внешних каналов связи, установка стабилизирующей и защитной аппаратуры для компенсации пиковых нагрузок, отказов и отключения энергопитания (ИБП), организация охлаждения и вентиляции, интеграция СКУД, сигнализации и средств пожарной безопасности. Причем, в идеале все инженерные комплексы требуют дублирования для повышения отказоустойчивости и компенсации возможных рисков.
И это мы еще не коснулись затрат на обслуживание всех этих комплексов, ремонты, диагностику, оплату труда обслуживающего персонала. При таком раскладе можно смело закладывать в бюджет минимум 1/4 миллиона в год на каждую полную стойку.
Конечно, есть менее затратный выход – размещение комплекса в коммерческом центре обработки данных. Однако клиенты, оценившие преимущества cloud-сервисов, быстро переходят к гибридным программам, а потом и вовсе заменяют большую часть соответствующей инфраструктуры cloud-решениями, отдавая “освобожденную” аппаратуру под другие задачи.
Выводы
Оценив вышеперечисленные нюансы, даже без учета математической составляющей и конкретных показателей становится понятно, что cloud-структуры лидируют по эффективности вложения средств и обеспечивают минимальные затраты на поддержание инфраструктуры.
Если вам интересно, как будет выглядеть сравнение стоимости cloud- и аппаратного проекта для вашего предприятия или бизнеса – обращайтесь, мы проведем все необходимые расчеты и наглядно проиллюстрируем итоги.