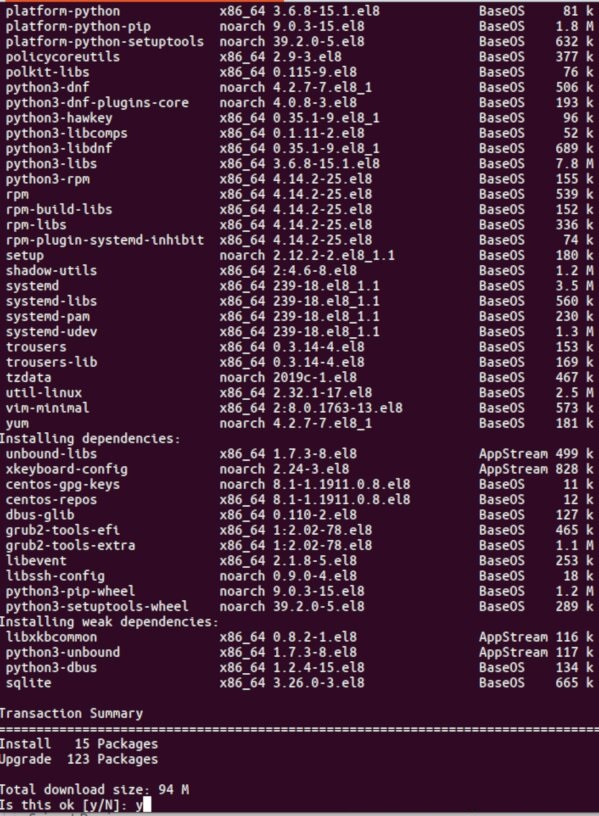
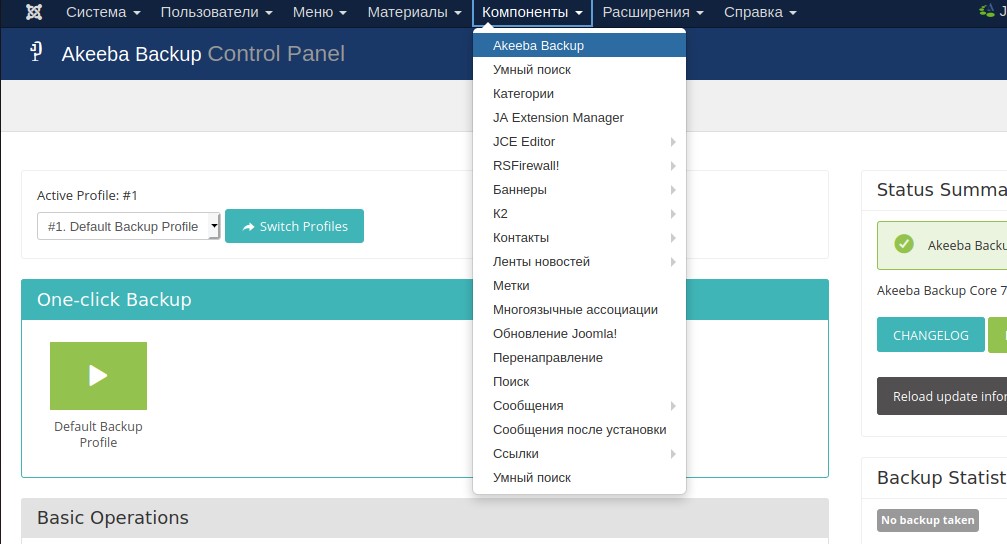
Инновации развиваются очень быстро, постоянно появляются новые технологии, меняющие контекст, в котором мы работаем. Соответственно, в таком динамичной среде нельзя стоять на месте – нужно непрерывно изучать новое и развиваться. В то же время важно правильно определить, на какую технологию сделать ставку сегодня, чтобы быть успешным завтра. Это в определенной степени лотерея. Теперь побеждают те, кто 5 лет назад поставил на Kubernetes, а не на Docker Swarm, или выбрал Azure вместо Oracle Cloud.
Я как директор решаю это не только для себя, но и для компании: в какие технологии нам инвестировать, в каком направлении развивать экспертов компании и что предлагать клиентам.
Как сделать правильный выбор? К счастью, мы можем не просто полагаться на удачу, а наблюдать, анализировать, ориентироваться на мировые тенденции, чтобы предсказать будущее и обеспечить себе сильные позиции в нем. Но перед тем, как смотреть в будущее, проанализируем уже пройденный путь.
С чего все начиналось и как эволюционировала роль Клауда
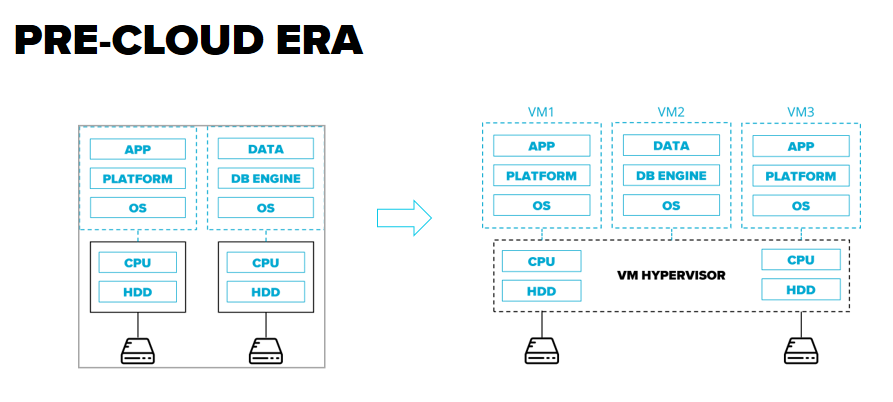
Краткий флэшбэк в эволюцию Клауд. Pre-Cloud – олдскул: серверы, роутеры, СЗД. Работаем с этим сами – устанавливаем ОС, получаем библиотеки и платформы, разворачиваем епликейшены, конфигурируем и автоматизируем. Дальше – интереснее.
На сцену выходят первые виртуальные машины и гипервизоры, управлять инфраструктурой становится значительно проще. В пределах одного сервера теперь можно выполнять гораздо больший объем задач. Инженеры постепенно смещают фокус с разработки инструментов и автоматизации на процессы – конфигурацию и совершенствования деливери платформы, эпликейшенов, инфраструктуры, целого решения. Виртуальные машины задали вектор развития на будущее.
Cloud 0 – в некоторых хостинг-компаний появляется идея продавать реальные серверы, а виртуальные, обеспечивая всю необходимую автоматизацию и работу по управлению инфраструктурой. Мы видим зарождение того, что в будущем получит название IaaS (Infrastructure as a Service). Но тогдашнему сервиса еще далеко до того, чтобы называться Клауд-провайдером.
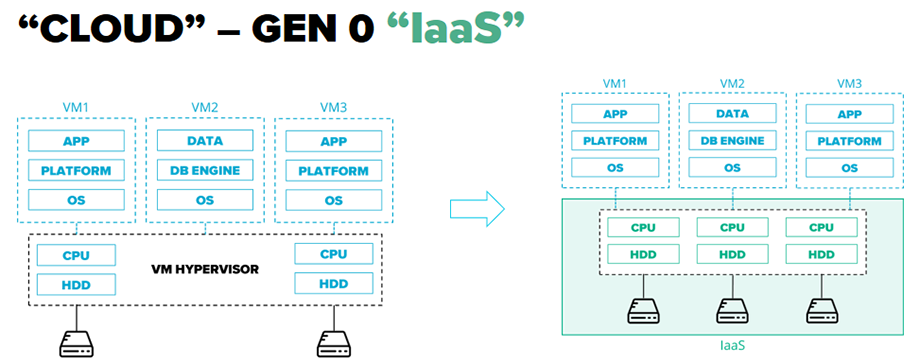
Cloud 1.0 – взлет Клауд-платформ. Появилось понимание, что большинство компаний используют те же ОС, платформы и фреймворки (Linux, Apache, PHP и т.д.). Это означает, что их можно автоматизировать, а инструменты для использования этих платформ – продавать как сервис. Появляются PaaS (Platforms as a Service), развивается тренд на использование публичных Клаудов. Инженеры получают новые инструменты для работы с платформами без необходимости разворачивать и поддерживать их самостоятельно. Объем рутинной технической работы становится еще меньше. Акцент в работе DevOps-инженера смещается на настройку платформы, наладка и развертывания решения на этой платформе, оптимизацию использования ресурсов, контроль за тем, насколько быстрым, понятным, гибким является весь процесс.
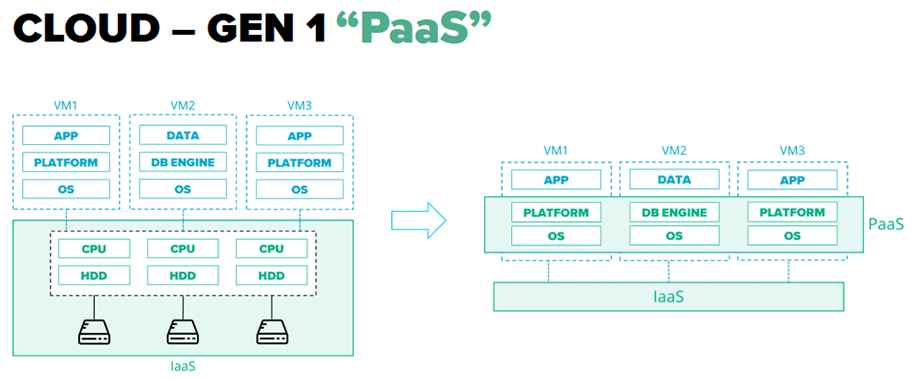
Cloud 2.0 – автоматизация распространяется не только на платформы, но и на некоторые традиционные сервисы (email, queues). Нам больше не надо думать об их развертывании, управлении ими и их масштабировании, поскольку появляется такой концепт, как Software as a Service (SaaS). Он меняет парадигму в сторону отказа от традиционного биллинга за серверные ресурсы (CPU / RAM / HDD) к оплате абонемента на сервис и использованных ресурсов епликейшен-уровня по размеру обработанных данных или количеством транзакций.
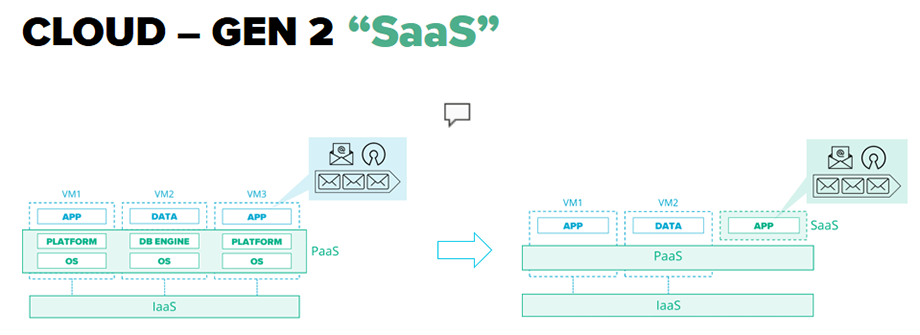
День Х – 7 июня 2014 года – первый публичный релиз Kubernetes. Черный день в истории Docker Swarm. Начинается эра Клауд-контейнеров, когда на смену традиционным виртуальным машинам для развертывания епликейшенов приходят контейнеры. Провайдеры очень быстро выпускают свои managed-решения для развертывания Kubernetes кластеров и управления ими. Появляются те поколения Клауд, которыми мы активно пользуемся сейчас.
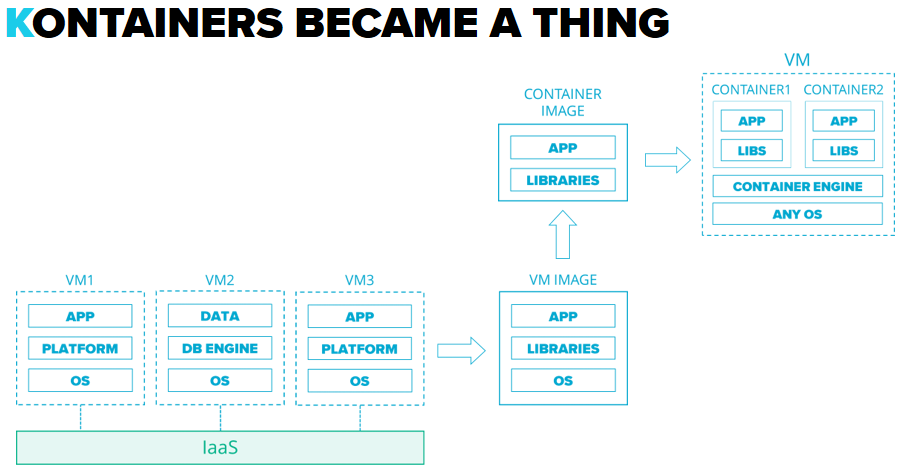
Cloud 2.5 – оркестраторы для контейнеров развиваются очень активно как ответ на установление глобального тренда на переход на микросервисну архитектуру в построении епликейшенов. Возникают Containers as a Service, позволяющие развернуть комплексную продакшен-архитектуру в Клауде всего за несколько часов или дней, в отличие от недель или месяцев, необходимых раньше.
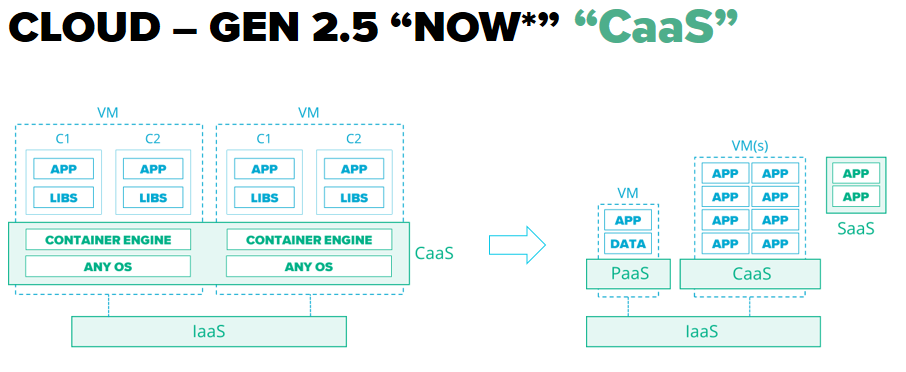
Cloud 3.0 – Functions as a Service (FaaS) – ответ на следующий этап эволюции, когда микросервисы становятся такими мелкими, что каждый из них отвечает за конкретную функцию. В то же время каждая функция полностью изолирована от другой. Соответственно, епликейшен разворачивается как ряд отдельных функций, каждую из которых можно привязать к другой или к любому ивента в системе или инфраструктуре.
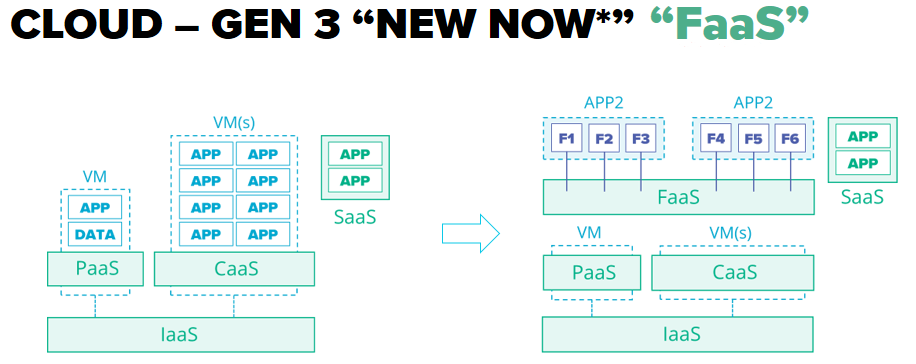
Как в свое время CaaS стал ответом на появление микросервиснои архитектуры, FaaS – ответ на дальнейшую эволюцию этой архитектуры и появление функций.
Как эволюция Клауд уже изменила DevOps
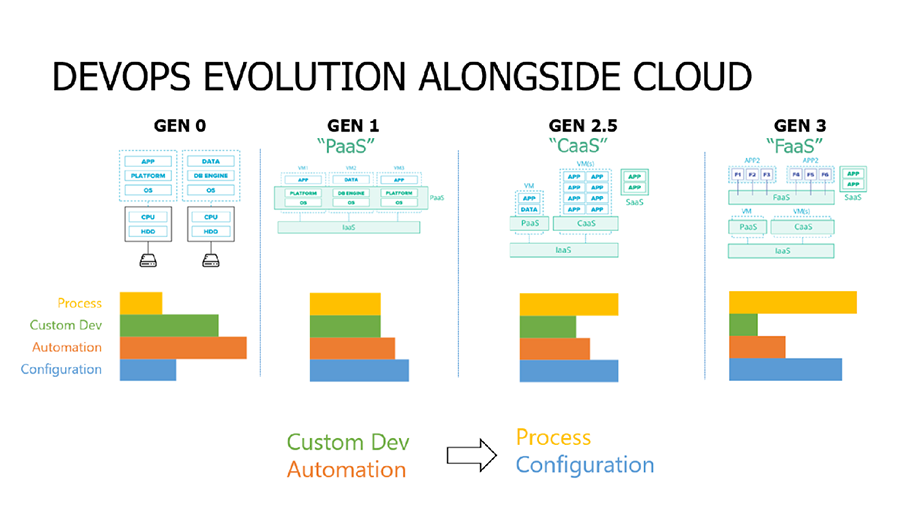
Когда мы располагали только серверы и даже когда появилась виртуализация, 80% времени DevOps-инженера шло на разработку и автоматизацию и только 20% – на процессы и конфигурацию платформы.
В Generation 3.0 большинство процессов уже автоматизировано. Все инструменты, которые появляются, освобождают нас от технической рутины, основная задача – уметь правильно ими пользоваться. То, что раньше делала команда за месяц, теперь может выполнить инженер самостоятельно за день. Для этого достаточно базовых технических знаний без углубления в подробности. Фокус сместился на настройку процессов, конфигурацию платформы, в отдельных случаях – минимальную автоматизацию и еще реже – потребность вручную дописать определенный компонент платформы.
Соответственно, кардинально меняются требования к DevOps-инженерам. Все чаще глубокие технические знания больше не дают конкурентное преимущество и не является ключом к успеху. Даже если столкнешься с определенными ограничениями платформы, то сможешь спланировать архитектуру так, чтобы их обойти. Теперь основная задача – наладить процессы, соединить между собой компоненты, и очень редко нам надо спускаться на уровень ниже, чтобы что-то подтюнинговать.
Что происходит теперь
По состоянию на 2019 Клауд – это must-have для энтерпрайз-компаний. 85% из них уже используют AWS или планируют перейти на них в следующем году. Немного меньший процент покрывают Azure, GCP. Кроме этого, доля Serverless, Container as a Service за год выросла на 40-50%. В наше время одна из трех компаний активно использует Serverless в продакшене, еще одна из трех – Container as a Service. Machine learning, IoT также растут, и за последующие 2-3 года доля этих технологий увеличится в два-три раза.
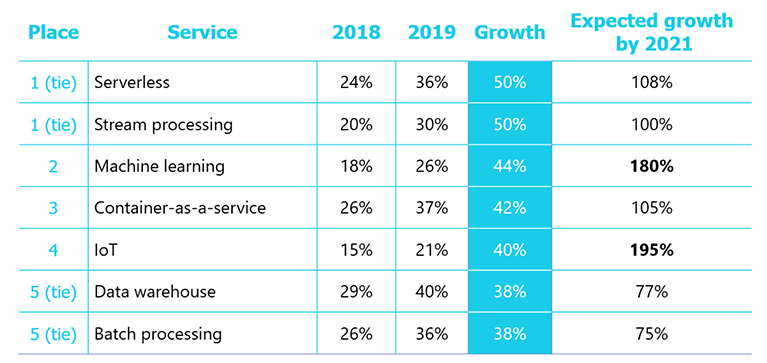
По данным State of the Cloud Report 2019.
Что дальше
Эволюция не прекращается. Зона экспертизы и ответственности DevOps-инженеров будет трансформироваться и в дальнейшем. Вот те технологические решения, которые будут развиваться и определять нашу профессию в средне- и долгосрочной перспективе.
Service mesh
Service mesh позволит эффективно управлять глобальными распределенными микросервиснимы (global distributed microservices) решениями на базе Kubernetes-платформы, которые продолжат стремительно развиваться в ближайшие годы. По данным исследований Gartner и IDC, в 2020 году все компании, которые применяют глобальную микросервисну архитектуру в продакшене, будут использовать Service mesh. Время покажет, какие конкретные инструменты выигрывают. Теперь лидирует Istio, второй по популярности – Linkerd, но это еще может измениться с выходом на рынок продуктов от таких гигантов, как HashiCorp, Red Hat и VMware.
Гибридные мультиклауды и Distributed clouds
Все, что мы рассмотрели выше, – это значительные изменения, которые происходят довольно быстро. Большим компаниям сложно к ним адаптироваться. В каждый этап они вкладывают большие инвестиции, которые не всегда успевают оправдать себя. К тому же корпорациям важно сохранять контроль над собственной инфраструктурой. Все это приводит к тому, что, внедряя что-то новое, они не могут отказаться от решений, в которые уже вложили средства, а нуждаются объединить все на одной площадке. Им становятся гибридные мультиклауды – комбинация имеющейся частной инфраструктуры с публичными провайдерами.
Многие Энтерпрайз рассматривают применение нескольких Клаудов – не только AWS, но также Azure, GCP и других, например, Alibaba Cloud, который так же быстро развивается в Азии, как и AWS в Северной Америке.
Однако неэффективно иметь 5 различных команд, инструментов, процессов и подходов, чтобы разворачивать тот же епликейшен для различных Клауд-сред. Поэтому энтерпрайз-компании обращают все больше внимания на платформы, которые унифицировали бы управление ими и оказывали бы инженерам один user experience. Поэтому стремительно развиваются такие платформы, как Pivotal и OpenShift. В ближайшее время эта тенденция не только сохранится, но и усилится.
Everything as a Service (XaaS)
С выходом на первый план платформ, унифицируются управления сервисами и абстрагируется инфраструктура, а также с последующими тенденциями Клауд-провайдеров предоставлять managed-решения исчезнет потребность в традиционных сервисах, которые надо настраивать и разворачивать вручную. В результате большинство платформ превратятся в managed-решения.
Эта тенденция сохранится и в ближайшем будущем количество платформ, которыми нужно будет управлять вручную, уменьшится до абсолютного минимума. Все превратится в managed-сервисы. Упростится интеграция таких сервисов между собой. Исчезнет необходимость в автоматизации и развертывании в таком виде, как мы это делали раньше. Custom development занимать минимальную долю нашего рабочего Лоуд.
Containers, Serverless, ML, IoT
До 2021 года Containers, Serverless удвоят свои показатели. Это означает, что 3 из 4 компаний будут их использовать. Использование ML, IoT возрастет втрое. Соответственно, инженерам, которые не хотят потерять свою работу за несколько лет, стоит это изучать.
DataOps, MLOps, IoTOps
Основные идеи DevOps-культуры распространятся на другие компетенции. С этого возникают новые течения, например DataOps – уже здесь, MLOps – начинает зарождаться и стабилизироваться, IoTOps – находится на хайпе, но на практике к стабильному и стандартизированного использования дойдем в течении нескольких лет. Подробнее об этих инструментах расскажу чуть ниже.
Predictive CICD and engineering performance
Например, если произойдет ошибка при слиянии кода, система автоматически извещать о ней и о причине, ее вызвавшей. То есть разработчики больше не должны будут тратить время на то, чтобы разобраться, почему-то не работает.
Казалось бы, Predictive CICD облегчит жизнь самим разработчикам, но не DevOps-инженерам. Хотя на самом деле это win-win для всех нас. Устранение человеческого фактора по написанию кода, где лишняя запятая может нарушить всю систему, – один из основных аспектов улучшения общей производительности проекта. И это значительный шаг вперед. Думаю, на это понадобится года 3-4, поскольку появляются новые и новые инструменты, позволяющие лучше собирать и обрабатывать данные, улучшается ML, что в конце приведет к полной автоматизации.
AIOps
В последующие несколько лет зародится новое течение AIOps, которое соединит в себе функционал big data и ML, чтобы частично или полностью освободить инженеров от тех операционных задач, которые они еще выполняют. Речь идет о availability- и performance-мониторинге, корреляции и анализе ивентов, менеджменте и автоматизации ИТ-сервисов. Решение по расширению или сужению инфраструктуры, переразворачиванию, перезагрузке сервиса, миграции платформа принимает уже автоматически, без участия инженеров.
Рассмотрим на конкретном примере. К чему может привести час простоя Facebook, Instagram или Netflix? К значительным финансовым потерям, снижениюцены акций, потери лояльности пользователей. А это может произойти даже через мелкую ошибку. Но что бы ни привело к неисправности, инженер должен осуществить работу, чтобы отыскать ее причину, а потом еще потратить время, чтобы ее устранить. А если это случается ночью, то к этому добавляется и время на то, чтобы он проснулся и включил компьютер. Решения, основанные на AI, все это выполнят в секунду.
DevOps будущего. Перспектива на 5+ лет
Все те процессы и изменения, которые мы рассмотрели выше, звучат так, будто мы рубим сук, на котором сидим. Ведь что останется мне, когда AI научится выполнять работу за меня?
Так, традиционный DevOps в нынешнем понимании постепенно исчезнет. Но появляться новые зоны ответственности надо будет оптимизировать процессы, подняться на уровень выше AI и работать более как data scientist, ML-инженер, анализировать данные.
Подобные изменения-парадигмы уже происходили при переходе с Cloud 1.0 на Cloud 2.0, когда мы начали фокусироваться на оптимизации процессов. Следующая волна произошла, когда исчезла потребность в ручной оптимизации.
Основной задачей DevOps-инженера станет собрать все элементы и объединить их в оптимизированную систему, чтобы обеспечить ее максимально эффективную работу. Это предполагает понимание того, как развернуть епликейшен и платформу, построить процессы и объединить их между собой так, чтобы избежать неисправностей. А как мы можем проверить, что этот прогресс действительно происходит? Без измерений и конкретных цифр – никак. Соответственно, надо будет измерять, анализировать и четко понимать все процессы. Работа DevOps-инженера будет тесно связана со сбором и анализом информации о работе целых платформ.
Мы уже начинаем это делать, и в ближайшее время это еще активнее набирать обороты. Те компании, которые сейчас работают по старой схеме, когда есть необходимость собственноручно писать много кода, постепенно также будут переходить на новую модель. С приходом в Клауд даже тех вертикалей, которые сейчас отстают (Healthcare и финансы), потребность в разработке и использовании кастомных решений для автоматизации исчезает. Соответственно, останутся процессы и конфигурация. А для тех, кто теперь впереди, добавятся ML и AI, которые помогут им работать с данными, научат их системы автоматически принимать решение на базе метрик и данных.
Предсказания на следующие 10 лет от Enterprise: в 80% компаний традиционная ИТ-часть организации, к которой принадлежит DevOps, уменьшится до минимального уровня. Operations- и development-специалисты будут работать с платформами, данными, аналитикой. Людей в компании, которые будут лезть в платформу, дописывать и подправлять, практически не останется.
К нам обращаются многие компании, которые на шаг отстают от этих тенденций, за помощью в прохождении такой трансформации. То есть все больше компаний начинают осознавать, насколько это важно. Тех, кто находится на этапах Cloud 0 или Cloud 1.0, мы переводим сразу на Cloud 3.0. Соответственно, рывок вперед происходит быстрыми темпами.
Те компании, которые эти этапы уже прошли, обращаются с точечными запросами, например помочь им настроить кост-менеджмент в Клауде или помочь построить новую платформу на базе FaaS / XaaS.
То есть мы понимаем, что среда будет меняться. Соответственно, тем, кто хочет успешно продолжать карьеру и иметь возможность работать на инновационных проектах, следует начинать адаптироваться к новым условиям уже сейчас.