Архитектура решения
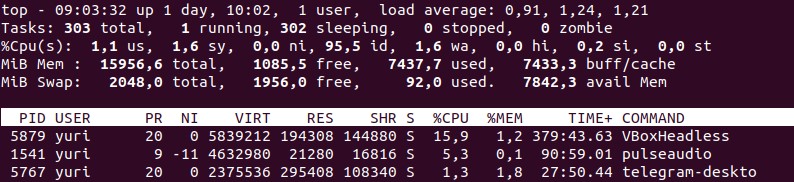
На уровне приложений: основное fpm,nginx, и solr для индексов и фильтров.
Также выделены окружения для разработки и тестирования.
Взаимодействие между ними и продуктивной средой:
Для тестирования есть QA Enviroment и есть Pre-Release Enviroment. Мы используем Jenkins. Там настроены deploy jobs так, что можно сделать деплой на QA с любой ветки. Если, например, выбрана ветка с именем 10, то развернутое приложение будет доступно по домену 10. То есть если разные QA инженеры тестируют разные ветки, то для каждого из них приложение будет доступно по разным доменам. Фактически это отдельно стоящие сервера, на которых, при деплое, разворачивается минимально необходимое для работы приложения окружение.
Pre-Release Environment – он полностью повторяет Production Environment. Разница между ним и QA в том, что если на QA используется одна база, и solr в одном экземпляре, то на Pre-Release будет так, как на Production: если на Production – solr-cloud и MariaDB в кластере, то они же будет и на Pre-Release. Это необходимо для того, чтобы с минимальными отличиями повторить Production Environment. Прикол в том, что на QA (из-за экономии средств) зачастую делается все на одном сервере, в то время как в Production Environment существует избыточность для обеспечения отказоустойчивости. Таким образом, в Production Environment обновление приложения может занять больше времени. А на QA будет сложно заметить, что база может оказаться заблокированной на 5-7 минут. Также, используя только QA, сложно оценить, насколько долго вообще будет проходить обновление в Production Environment. Для выявления таких вот особенностей поведения приложения в Production и нужен Pre-Release Environment.
Что касается взаимодействия – суть в том, чтобы прописать jobs на Jenkins так, чтобы больше никуда не лазить. Нужно разливать QA – раздал права на развертывание QA инженерам и все. Непосредственно развертывание выполняется автоматически без участия администратора. Возможность развертывания Production версии в нашей компании доверена только TeamLead’ам. Также нужно автоматизировать задачи восстановления среды после тестирования. Вообще автоматизировать нужно все, что можно автоматизировать. Такова идеология. И она себя оправдывает.
Есть еще окружение разработчика. Оно индивидуально для каждого программиста.
Процесс работы с Development, QA, Production
Development среда настраивается с помощью Vargant и Ansible. То есть приходит новый разработчик. Ему выдают отдельную машину, на которой он устанавливает желаемую ОС и VirtualBox+ Vargant. Далее он запускает background task, и в течение 1,5 часов ему накатывается вся необходимая среда. Таким образом, нет Development окружения на сервере. У каждого девелопера оно локально на своем тазике. Такой подход используется потому что есть разные ОС под которыми работают: и винда, и маки, и друие. Если разворачивать Development Environment с помощью докера, могут быть проблемы у тех, кто использует Windows, например. Именно по этому был изначально выбран VirtualBox и Vargant. То есть Vargant запускает уже готовые боксы, со внутренностями которых уже работает Ansible. Плюс такого решения в его кроссплатформенности.
Реализация QA
QA реализован на отдельных серверах. А Development Environment – это не отдельный сервер с виртуальной машиной на VirtualBox под каждого разработчика. Когда то была такая практика, но она себя не оправдывает. Слишком много возни с сервером, и раздачей прав. Пришли к тому, что у каждого разработчика стоит «тазик» с 16 ГБ и Core i7. Для настройки рабочей машины, он делает gitClone с репозитария, где лежит файл скрипта и плейбуки Ansible. Разработчик локально ставит себе виртуальную машину с полным окружением для проекта. То есть у каждого программиста локально стоит все окружение. Это распределенная система.
Для того, чтобы автоматизировать развертывание рабочего места можно в Jenkins создать job для сборки образа и дать разработчику несколько вариантов настройки своего окружения: либо самому запустить скрипты и подождать час-полтора пока это все накатится, либо скачать с сервера готовый образ виртуальной машины. Второй вариант может быть плюсом, когда криворукий программист что-то напортачил, и нет времени и\или желания с этим разбираться. Даешь образ и все готово.
Проблема различных версий php, модулей, и прочего ПО
Мы решаем эти вопросы, тем, что разработчик имеет рута на своей виртуальной машине. А если он понаставил чего-то там и оно не работает, то мы даем ему чистый стандартный образ, и он может продолжать свои эксперименты. Суть в том, что у нас нет времени с этим разбираться. Есть стандартный образ, в котором все работает.
Одного образа на всех у нас нет. Есть проект, и есть требования под проект. Это можно сделать, но только если есть необходимость.
Например, мы сейчас переезжаем на Symphony 3 и нужен php 7.1. Я на Ansible делаю инсталляцию 7.1. и, да, на Development Environment я имею несколько версий php. Например, на rpm порту 9000 – php 5.6, на 9001 – 7.1, и в nginx разруливаю уже хостами. Для переключения консольной версии используем скрипт. Нужно переехать – запусти скрипт. Нужно обратно – еще раз запусти. Жалоб на такое решение пока не было.
Используются ли какие-то инструменты по управлению кроме Vargant? Речь сейчас не только о Development Environment.
Тут важен подход: где все это будет в облаке или на обычном хосте. Например, работая в облаке, мы больше использовали копирования образов, хотя в запасе всегда был Ansible, который умел все это разворачивать. Сейчас в наземной инфраструктуре Ansible основной инструмент.
Это был Development Environment. QA – это сервера, на которых уже настроена некоторая среда.
Процедуры, которые выполняются при переходе с Development на QA
Когда разработчик готов, он делает push-request, ТимЛид проверяет и подтверждает push-request, push-request попадает в репозитарий кода, в Jira программист передает задачу на QA-инженера. Тестировщик видит, что разработчик закончил работу над задачей под такой-то веткой. Тогда он самостоятельно заходит в Jenkins и запускает job для деплоя с такой-то ветки. Допустим у нас ветка mmm. В процессе запуска QA-инженер делает «bulk with parameters», Jenkins делает запрос в Bitbucket, предоставляя возможность выбора нужной ветки, QA-инженер выбирает mmm и клацает «ОК». Для него собирается проект на QA серверах из ветки mmm. Собранный проект доступен по адресу mmm.<внутренний домен>
Собирается все с помощью Composer install – php-шный composer.
Тест кода на данном этапе
В этом нет необходимости, но если это нужно, то делается это так. В Jenkins есть возможность запустить новый job автоматически, если предыдущий завершился успешно. То есть мы говорим об автоматизированных QA проверках, которые запускаются, после того, как задача по развертыванию проекта успешно завершена и проект доступен по запланированному домену. Сами php-юниты запускаются при инсталляции. Если они не прошли, то деплой проекта завершится неуспешно. Уведомление об этом получает вся группа. Далее изучаются логи и определяются причины сбоя.
Вопрос о правах
У Jenkins есть матрица безопасности (Matrix Security). Когда она включена, имеется возможность для каждого сотрудника (разработчика, QA-инженера) заводить пользователя, и потом на каждый конкретный Job раздавать права конкретному пользователю. Раздача прав выполняется согласно потребностям и ролям, которые человек выполняет в команде. Каждая компания в этом практически уникальна.
Стресс тесты на QA
Стресс тесты имеет смысл выполнять на Pre-release environment, поскольку эта среда максимально похожа на продуктивную. Поиском потерянных линков, также должны заниматься QA-инженеры, которые тестируют пред-релиз. В качестве альтернативы – есть автоматизированные тесты на Selenium, которые бегают по сайту и клацают на все, что можно. Эти автоматизированные тесты выполняются после успешно выполненной предрелизной сборки. И Если тест не пройдет, то вся сборка будет неудачной, о чем все узнают.
Обновление Production environment: автоматически или нет?
И да и нет. Есть Jenkins Job, который это делает. Но он не делает это автоматически. У нас есть отдельные QA-инженеры, которые тестируют работу приложения в Pre-release environment. Когда они готовы, они меняют статус задачи в Жира. ТимЛид видит что QA-инженеры закончили тестирование такой-то фитчи, в такой-то ветке и можно обновлять «боевое» приложение. Он нажимает в Jenkins кнопку «Deploy» и система запускает процесс изменения продуктивной среды.
Главная задача здесь сделать так, чтобы тебя никто не отвлекал с вопросами: «ну что – задеплоилось?», «а на чем сломалось?». Все должны иметь возможность действовать и по результатам этих действий все должны быть оповещены. Тогда они варятся в собственном соку, давая тебе спокойно работать. А ты собственно туда не лазишь, занимаясь своей работой.
Об архитектуре приложения
У нас Galera Cluster. Не тормозит, есть некоторые задержки, но они измеряются в миллисекундах и долях миллисекунд. Но в нашем случае базы не находятся в разных дата-центрах. Они все подключены в один гигабитный свитч.
Базы в разных дата-центрах будут, но позже. Будет тоже Galera Cluster. Там нужно настраивать группы, чтобы они между собой реплицировались. Если у тебя есть кластер Galera в одном дата-центре и кластер Galera в другом (для отказоустойчивости), то за счет правильной настройки групп Galera сама знает задержки и тормозов из-за этого не должно быть. Мы уже проверили это на тестовом стенде. Но нужно понимать, что имея подобную схему не нужно писать и на тот и на тот кластер. То есть один дата-центр принимает, и на второй реплицирует, в случае падения принимать начинает второй. В таком случае падение одного сервера баз данных будет незаметным для конечного пользователя. А одновременно принимать данные в два дата-центра я бы не советовал.
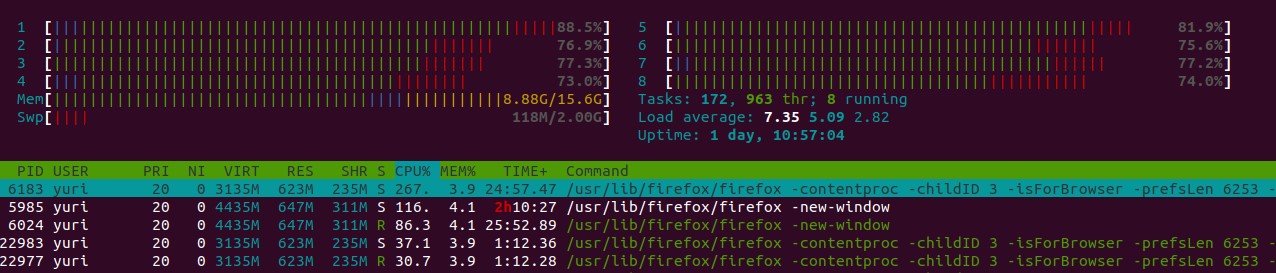
Фронтов у нас 16 из-за большого объема трафика.
16 хостов, 3 балансировщика (HA-proxy) с проверкой позади фронтов. Также cloudflare используем: она cdn-ом выступает.
Galera для разгрузки mySQL
Galera проектировалась изначально. Если бы не было Galera Cluster, был бы какой-то master\slave или master\ master, но с возможностью записи в один. Мне не нравится использование master\slave архитектуры в условиях динамически меняющейся инфраструктуры. В условиях Galera Cluster это все проще. Она позволяет решить и задачи отказоустойчивости и балансировки одновременно.
Но все равно при этом стоит HA-proxy перед базами и у него на порт 3308 приходят данные на запись, 3307 – запросы на чтение. 3308 – master, 3307 – slave. Это то, что знает приложение. Но HA-proxy балансирует нагрузку: запись все-равно на один сервер, а чтение на все остальные. Если сервер для записи не отвечает, то HA-proxy переключит на другой сервер записи. Нет такой проблемы, когда нужно что-то делать при падении мастера или писать скрипты, которые отработают в этой ситуации. При тестировании пробовали писать на две ноды – проблемы не обнаружили.
Для индексов и фильтров используем solr. На большом проекте фильтры через mySQL сильно нагружают его.
Как в Solr решаются задачи поддержания актуального состояния индекса при частых изменениях данных
Это называется кэш. Solr же все вытягивает из MySQL, кеширует грубо говоря. Поэтому этот вопрос – не проблема.
Мы же говорим о большом проекте. В нем – отдельно фронты, отдельно бэк, и еще отдельно бек с кронами с тасками, грубо говоря Working сервер, который выполняет периодические задачи.
У Solr есть такая штука – дельта индекс. Работает это следующим образом. Есть полное индексирование, и есть дельта индексирование. При полном индексировании Solr где-то у себя сгружает то, что он накэшил и пока не закончится индексация, он не заменяет имеющуюся информацию.
При выполнении дельта индексирования из MySQL вытягиваются только изменения. У нас 2 000 000 товаров . Дельта индекс выполняется каждые 3 минуты и длится секунд 40. Полное индексирование проходит за 2-3 часа. Логика такая: Solr постоянно делает дельту, а во время минимальной нагрузки (в нашем случае – ночью) он делает полное индексирование. Это настраивается php-скриптами, которые запускаются по расписанию. При этом Solr умный, и если выполняется запущено полное индексирование, он не запустит дельта-индексирование. При попытке запуска будет получено сообщение типа «Извини, но я еще в процессе выполнения создания полного индекса».
А можно же поставить 2 сервера: на одном в этот момент выполняется полное индексирование, в то время как второй обслуживает запросы?
Тут нет проблемы в том, что он не принимает запросы. Он нормально работает. В процессе полного индексирования, Solr успешно принимает запросы и отдает данные. В этом нет проблем.
Solr Cloud
При использовании Solr Cloud есть ведущий сервер, и есть подчиненный. Когда на лидере у тебя проходит полное индексирование, он (как и в случае одного сервера) может принимать и отдавать данные. Нет каких-либо блокировок. Когда на первом узле создается полный индекс, задача второй – ждать изменений. Лидер не применяет изменений пока не закончится индексирование ядра. Когда это завершено, ведущий сервер начинает «выливать» на подчиненные все изменения. По-моему, он просто копию файла делает.
Кэш при добавлении или изменении индекса
Товары добавляются дельта индексом и при этом кэш не сбрасывается. Но есть нюанс. Добавление или изменение товаров, то есть обновление кэша вследствие изменения данных, в базе он делает с помощью дельта индексирования, но если в таблицу добавлено новое поле, то нужно делать полное индексирование. То есть Solr не сможет дельтой стянуть новое поле, потому что он об этом поле ничего не знает. Исходя из этого, при добавлении полей или изменении настроек необходимо пересоздавать полный индекс. Ответ на вопрос – Solr не скидывает кэш самостоятельно, только если указать опцию «clear All» при запуске полной индексации.
Как все это резервировать?
Основное это база. Ночью делаем дамп и каждые 30 минут – инкрементальный на EXABackup.
Для Solr есть url-request. А фронты – зачем их резервировать, если их 16? Есть бекап на Bacula, который сохраняет некоторые конфиги, но им ни разу не пользовались. И нет уверенности, что будут. Поскольку их 16 и есть Ansible, который их раскатывает. Если упало сразу много хостов, то как только подняты новые сервера, накатывается окружение с помощью Ansible и поверх деплоится приложение.
Что мониторится и как отслеживается
Внутри – Zabbix – он мониторит. Для сбора статистики, анализа и понимания, что происходит – Grafana. Собирает множество метрик. Если что-то лагает – там можно найти объяснения. И внешней – Monitis. Я за то, чтобы не использовать лишнее ПО, поэтому иногда я пользуюсь хитростями. Например, для того, чтобы без агента мониторить базу через Monitis, я поднимаю apache на 81 порту, за которым слежу с помощью Monitis. Далее я пишу скрипт, который проверяет состояние базы, и если она упала – опускает apache. Что в свою очередь отслеживает Monitis. Возможно, это не пример для подражания, но почту от Zabbix я не читаю, смотрю консоль пару раз в день, а sms от Monitis мне и ночью прийдет. Таким образом, отслеживаю критические моменты, которые происходя прозрачно для пользователя приложения.
Качество кода
Плохой код не должен проходить на уровне QA. Если же это не отследили, и проблема попала в продуктивную среду, необходимо просто откатиться на одну сборку назад с помощью Jenkins. То есть при деплое должно быть 5 сборок в Production Environment, чтобы можно было сделать откат на любую из них. Это все решается линками . Если такое случилось – откатываем назад, ищем в Grafana и смотрим, где были нагрузки и почему . В Grafana метрики должны быть по максимуму по всем серверам, сервисам и приложениям.
И что самое главное, практически весь стек бесплатный.