Давайте продолжим и погрузимся глубже в то, как выглядит парсер show lldp neighbors, как он работает и как нам нужно изменить существующий playbook, чтобы использовать парсеры Genie.
Genie Primer
Количество парсеров резко увеличилось за последние несколько месяцев и начинает включать больше поставщиков, что приятно видеть.
Genie использует классы Python для создания двух важных функций синтаксического анализа:
- Класс схемы: этот класс определяет схему, которой должен придерживаться структурированный вывод.
- Класс синтаксического анализатора: этот класс определяет фактические методы синтаксического анализа для конкретной команды.
Одно из ключевых различий между тем, что мы рассмотрели до сих пор, и синтаксическими анализаторами Genie – это возможность подключаться к устройствам и получать необходимый вывод, что является поведением по умолчанию, но также позволяет пользователям предоставлять вывод вместо этого, таким образом работая как большинство синтаксических анализаторов, которые отдельно от взаимодействия с устройством.
Еще одно ключевое отличие – это возможность использовать другие стратегии синтаксического анализа в Genie, такие, как TextFSM или Template Text Parser (TTP), но в этом посте мы рассмотрим RegEx.
Давайте углубимся в наш конкретный парсер.
"""show_lldp.py
supported commands:
* show lldp
* show lldp entry *
* show lldp entry [<WORD>]
* show lldp interface [<WORD>]
* show lldp neighbors
* show lldp neighbors detail
* show lldp traffic
"""
import re
from genie.metaparser import MetaParser
from genie.metaparser.util.schemaengine import Schema, \
Any, \
Optional, \
Or, \
And, \
Default, \
Use
# import parser utils
from genie.libs.parser.utils.common import Common
Мы видим, что этот парсер объявлен в show_lldp.pyмодуле и поддерживает несколько вариантов команды show lldp . Затем он импортирует re, который является встроенной библиотекой RegEx. Следующий импорт – MetaParserэто проверка того, что выходные данные парсеров с0щоответствуют определенной схеме. После MetaParserимпорта происходит связанный со схемой импорт, который помогает построить реальную схему, которую мы вскоре увидим. После этого импортируется класс Common, который предоставляет вспомогательные функции.
Класс схемы дает нам представление о том, как будет выглядеть результат. Давайте посмотрим на первоначальное определение.
class ShowLldpNeighborsSchema(MetaParser):
"""
Schema for show lldp neighbors
"""
schema = {
'total_entries': int,
'interfaces': {
Any(): {
'port_id': {
Any(): {
'neighbors': {
Any(): {
'hold_time': int,
Optional('capabilities'): list,
}
}
}
}
}
}
}
Мы видим, что ShowLldpNeighborsSchemaэто будет подкласс MetaParserкласса, импортированного в начале файла. Внутри ShowLldpNeighborsSchemaкласса мы определяем наш schemaатрибут, используемый, чтобы убедиться, что наш вывод соответствует схеме, прежде чем возвращать его пользователю.
Схема является словарем и ожидает total_entriesключ с целочисленным значением и interfacesключом, используемым для определения словаря. Каждый интерфейс будет ключом в interfacesсловаре, а данные, полученные из выходных данных, определены в нескольких других вложенных словарях. Каждая пара “ключ-значение” определяет ключ и typeзначение, которым он должен быть. Также существуют Optionalключи, которые не требуются для проверки схемы.
Теперь, когда мы видим схему, мы можем смоделировать, каким будет наш потенциальный результат.
{
"total_entries": 1,
"interfaces": {
"GigabitEthernet1": {
"port_id": {
"Gi1": {
"neighbors": {
"iosv-0": {
"capabilities": [
"R"
],
"hold_time": 120
}
}
}
}
}
}
}
Перейдем к определенному классу парсера.
class ShowLldpNeighbors(ShowLldpNeighborsSchema):
"""
Parser for show lldp neighbors
"""
CAPABILITY_CODES = {'R': 'router',
'B': 'mac_bridge',
'T': 'telephone',
'C': 'docsis_cable_device',
'W': 'wlan_access_point',
'P': 'repeater',
'S': 'station_only',
'O': 'other'}
cli_command = ['show lldp neighbors']
Мы видим, что ShowLldpNeighborsкласс наследует ShowLldpNeighborsSchemaкласс, который мы только что рассмотрели. Теперь есть сопоставление для коротких кодов возможностей формы, возвращаемых в выходных данных, когда соседи существуют, и для длинной формы, которую синтаксический анализатор хочет вернуть пользователю.
Следующая определенная переменная – это cli_command. Он определяет команды, выполняемые синтаксическим анализатором, если выходные данные не предоставляются.
Давайте посмотрим на cliметод, чтобы увидеть, что будет выполнено, когда пользователь укажет cliсинтаксический анализатор для show lldp neighborsкоманды.
Каждый тип вывода будет указан как метод в классе парсера. Например, если устройство возвращает xml, будет xmlметод, который будет анализировать и возвращать структурированные данные, которые придерживаются той же схемы, что и cliвыходные данные.
Давайте рассмотрим код по частям, чтобы показать, что происходит.
def cli(self, output=None):
if output is None:
cmd = self.cli_command[0]
out = self.device.execute(cmd)
else:
out = output
parsed_output = {}
Мы видим, что cliметод принимает необязательный аргумент с именем output, но по умолчанию None. Первая логика определяет, предоставил ли пользователь команду outputили нужно ли синтаксическому анализатору выполнить команду в отношении устройства. Используемое парсером соединение обеспечивается библиотекой PyATS. Это означает, что никакой другой библиотеки, такой как netmikoили napalmдля подключения к устройствам, не требуется.
# Total entries displayed: 4
p1 = re.compile(r'^Total\s+entries\s+displayed:\s+(?P<entry>\d+)$')
# Device ID Local Intf Hold-time Capability Port ID
# router Gi1/0/52 117 R Gi0/0/0
# 10.10.191.107 Gi1/0/14 155 B,T 7038.eeff.572d
# d89e.f3ff.58fe Gi1/0/33 3070 d89e.f3ff.58fe
p2 = re.compile(r'(?P<device_id>\S+)\s+(?P<interfaces>\S+)'
r'\s+(?P<hold_time>\d+)\s+(?P<capabilities>[A-Z,]+)?'
r'\s+(?P<port_id>\S+)')
parsed_outputСледующим шагом после создания переменной является определение выражений RegEx, используемых для поиска ценных данных в выходных данных устройства. Поскольку выходные данные представлены в виде таблицы, что означает, что они определены как таблица, все значения, которые нам нужны, будут в одной строке (строке) для каждого соседа.
Анализатор использует, re.compileчтобы заранее указать выражение RegEx для последующего использования в коде. Обычно re.compileиспользуется, когда одно и то же выражение используется несколько раз.
p1предоставит total_entriesв нашей схеме, используя возможность именованных групп захвата в reбиблиотеке. К счастью, Cisco предоставляет отличную документацию в коде, чтобы рассказать вам, что ожидает захватить каждое регулярное выражение. p2определяет регулярное выражение, используемое для сбора информации о соседях. Мы видим, что он использует в основном те, \S+которые захватывают любые непробельные символы, поскольку вывод является прямым. Но мы видим возможности названой группы захвата немного сложнее. Ожидается хотя бы одна заглавная буква или запятая, а затем ноль или одно из этого выражения RegEx. Это можно лучше объяснить на их примере, если мы посмотрим на столбец возможностей, он показывает, что он может фиксировать одну возможность, две возможности с запятой или нулевые возможности.
Теперь давайте посмотрим на оставшийся код, чтобы увидеть, как он использует эти выражения RegEx.
for line in out.splitlines():
line = line.strip()
# Total entries displayed: 4
m = p1.match(line)
if m:
parsed_output['total_entries'] = int(m.groupdict()['entry'])
continue
# Device ID Local Intf Hold-time Capability Port ID
# router Gi1/0/52 117 R Gi0/0/0
# 10.10.191.107 Gi1/0/14 155 B,T 7038.eeff.572d
# d89e.f3ff.58fe Gi1/0/33 3070 d89e.f3ff.58fe
m = p2.match(line)
if m:
group = m.groupdict()
intf = Common.convert_intf_name(group['interfaces'])
device_dict = parsed_output.setdefault('interfaces', {}). \
setdefault(intf, {}). \
setdefault('port_id', {}). \
setdefault(group['port_id'], {}).\
setdefault('neighbors', {}). \
setdefault(group['device_id'], {})
device_dict['hold_time'] = int(group['hold_time'])
if group['capabilities']:
capabilities = list(map(lambda x: x.strip(), group['capabilities'].split(',')))
device_dict['capabilities'] = capabilities
continue
return parsed_output
Мы видим, что синтаксический анализатор выполняет forцикл по выходным splitlinesданным, используя метод для предоставления списка каждой строки в выходных данных. Он удалит любые пробелы с обеих сторон строки.
Синтаксический анализатор попытается сопоставить p1скомпилированный RegEx и, если он его захватит, добавит total_entriesв parsed_outputсловарь, а затем continueв следующую строку вывода.
Если синтаксический анализатор ничего не захватил p1, он попытается сопоставить p2. Если совпадение произойдет, groupdict()метод вернет все названные группы захвата и их значения в виде словаря.
Теперь мы видим, что парсер использует convert_intf_nameметод из Commonкласса, импортированного в верхней части файла.
После преобразования имени интерфейса синтаксический анализатор добавляет interfacesсловарь к parsed_outputпеременной, извлекая захваченную информацию или по умолчанию в пустой словарь для любых не захваченных данных, а затем присваивая ее device_dictпеременной.
После того, device_dictкак указан, он добавляет к нему время удержания.
Следующим шагом является разделение возможностей на список и добавление к device_dictпеременной. Затем синтаксический анализатор перейдет к следующей строке вывода.
Как только все строки будут проанализированы, он вернет parsed_outputпользователю, если он пройдет проверку схемы.
Я считаю, что это легче понять, чем что-то вроде TextFSM, поскольку он написан на Python, а Python – популярный язык среди инженеров по автоматизации сети.
Давайте продолжим и еще раз рассмотрим топологию.
Топология .. Опять же
Ниже приведено изображение лабораторной топологии, которую мы используем для проверки соседей LLDP . Это простая топология с тремя маршрутизаторами Cisco IOS, соединенными вместе и с включенным протоколом LLDP.
Ansible Setup .. Опять же
Мы уже рассмотрели большую часть настройки Ansible, но мы объясним небольшие изменения, которые мы должны внести, чтобы использовать парсеры Genie в Ansible.
Вот взгляд на host var, который мы определили как освежитель, поскольку здесь нет никаких изменений.
---
approved_neighbors:
- local_intf: "Gi0/0"
neighbor: "iosv-1"
- local_intf: "Gi0/1"
neighbor: "iosv-2"
Теперь посмотрим на изменения в pb.validate.neighbors.yml.
---
- hosts: "ios"
connection: "ansible.netcommon.network_cli"
gather_facts: "no"
tasks:
- name: "PARSE LLDP INFO INTO STRUCTURED DATA"
ansible.netcommon.cli_parse:
command: "show lldp neighbors"
parser:
name: ansible.netcommon.pyats
set_fact: "lldp_neighbors"
- name: "MANIPULATE THE DATA TO BE IN THE SAME FORMAT AS TEXTFSM TO PREVENT CHANGING FINAL ASSERTION TASK"
set_fact:
lldp_neighbors: "{{ lldp_neighbors | convert_data }}"
- name: "ASSERT THE CORRECT NEIGHBORS ARE SEEN"
assert:
that:
- "lldp_neighbors | selectattr('local_interface', 'equalto', item['local_intf']) | map(attribute='neighbor') | first == item['neighbor']"
loop: "{{ approved_neighbors }}"
Используя ansible.netcommon.pyatsанализатор требует genieи pyatsдолжен быть установлен с помощью pip install genie pyats.
Есть несколько вещей, которые нужно проанализировать с помощью учебника. Сначала мы изменили парсер на ansible.netcommon.pyats. Во-вторых, мы добавили еще одну задачу для управления данными, которые мы получаем от парсера, в формате, аналогичном второму сообщению в блоге в этой серии, поэтому нам не нужно изменять последнюю задачу. Я выполнил преобразование с помощью настраиваемого плагина фильтра из-за структуры данных и простоты обработки в Python. Вы увидите результат ниже, как только мы запустим нашу книгу.
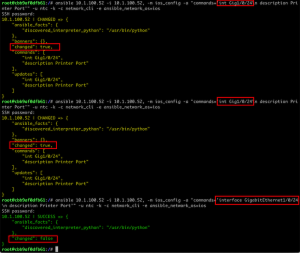
❯ ansible-playbook pb.validate.neighbors.yml -k -vv
ansible-playbook 2.10.3
config file = /Users/myohman/Documents/local-dev/blog-posts/ansible.cfg
configured module search path = ['/Users/myohman/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /Users/myohman/.virtualenvs/3.8/main/lib/python3.8/site-packages/ansible
executable location = /Users/myohman/.virtualenvs/3.8/main/bin/ansible-playbook
python version = 3.8.6 (default, Nov 17 2020, 18:43:06) [Clang 12.0.0 (clang-1200.0.32.27)]
Using /Users/myohman/Documents/local-dev/blog-posts/ansible.cfg as config file
SSH password:
redirecting (type: callback) ansible.builtin.yaml to community.general.yaml
redirecting (type: callback) ansible.builtin.yaml to community.general.yaml
Skipping callback 'default', as we already have a stdout callback.
Skipping callback 'minimal', as we already have a stdout callback.
Skipping callback 'oneline', as we already have a stdout callback.
PLAYBOOK: pb.validate.neighbors.yml ***********************************************************************
1 plays in pb.validate.neighbors.yml
PLAY [ios] ************************************************************************************************
META: ran handlers
TASK [Parse LLDP info into structured data] ***************************************************************
task path: /Users/myohman/Documents/local-dev/blog-posts/pb.validate.neighbors.yml:9
ok: [iosv-2] => changed=false
ansible_facts:
lldp_neighbors:
interfaces:
GigabitEthernet0/0:
port_id:
Gi0/1:
neighbors:
iosv-0:
capabilities:
- R
hold_time: 120
GigabitEthernet0/1:
port_id:
Gi0/1:
neighbors:
iosv-1:
capabilities:
- R
hold_time: 120
total_entries: 2
parsed:
interfaces:
GigabitEthernet0/0:
port_id:
Gi0/1:
neighbors:
iosv-0:
capabilities:
- R
hold_time: 120
GigabitEthernet0/1:
port_id:
Gi0/1:
neighbors:
iosv-1:
capabilities:
- R
hold_time: 120
total_entries: 2
stdout: |-
Capability codes:
(R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device
(W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other
Device ID Local Intf Hold-time Capability Port ID
iosv-1 Gi0/1 120 R Gi0/1
iosv-0 Gi0/0 120 R Gi0/1
Total entries displayed: 2
stdout_lines: <omitted>
ok: [iosv-0] => changed=false
ansible_facts:
lldp_neighbors:
interfaces:
GigabitEthernet0/0:
port_id:
Gi0/0:
neighbors:
iosv-1:
capabilities:
- R
hold_time: 120
GigabitEthernet0/1:
port_id:
Gi0/0:
neighbors:
iosv-2:
capabilities:
- R
hold_time: 120
total_entries: 2
parsed:
interfaces:
GigabitEthernet0/0:
port_id:
Gi0/0:
neighbors:
iosv-1:
capabilities:
- R
hold_time: 120
GigabitEthernet0/1:
port_id:
Gi0/0:
neighbors:
iosv-2:
capabilities:
- R
hold_time: 120
total_entries: 2
stdout: |-
Capability codes:
(R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device
(W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other
Device ID Local Intf Hold-time Capability Port ID
iosv-2 Gi0/1 120 R Gi0/0
iosv-1 Gi0/0 120 R Gi0/0
Total entries displayed: 2
stdout_lines: <omitted>
ok: [iosv-1] => changed=false
ansible_facts:
lldp_neighbors:
interfaces:
GigabitEthernet0/0:
port_id:
Gi0/0:
neighbors:
iosv-0:
capabilities:
- R
hold_time: 120
GigabitEthernet0/1:
port_id:
Gi0/1:
neighbors:
iosv-2:
capabilities:
- R
hold_time: 120
total_entries: 2
parsed:
interfaces:
GigabitEthernet0/0:
port_id:
Gi0/0:
neighbors:
iosv-0:
capabilities:
- R
hold_time: 120
GigabitEthernet0/1:
port_id:
Gi0/1:
neighbors:
iosv-2:
capabilities:
- R
hold_time: 120
total_entries: 2
stdout: |-
Capability codes:
(R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device
(W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other
Device ID Local Intf Hold-time Capability Port ID
iosv-2 Gi0/1 120 R Gi0/1
iosv-0 Gi0/0 120 R Gi0/0
Total entries displayed: 2
stdout_lines: <omitted>
TASK [MANIPULATE THE DATA TO BE IN STANDARD FORMAT] *******************************************************
task path: /Users/myohman/Documents/local-dev/blog-posts/pb.validate.neighbors.yml:16
ok: [iosv-0] => changed=false
ansible_facts:
lldp_neighbors:
- local_interface: Gi0/1
neighbor: iosv-2
- local_interface: Gi0/0
neighbor: iosv-1
ok: [iosv-1] => changed=false
ansible_facts:
lldp_neighbors:
- local_interface: Gi0/1
neighbor: iosv-2
- local_interface: Gi0/0
neighbor: iosv-0
ok: [iosv-2] => changed=false
ansible_facts:
lldp_neighbors:
- local_interface: Gi0/1
neighbor: iosv-1
- local_interface: Gi0/0
neighbor: iosv-0
TASK [Assert the correct neighbors are seen] **************************************************************
task path: /Users/myohman/Documents/local-dev/blog-posts/pb.validate.neighbors.yml:20
ok: [iosv-0] => (item={'local_intf': 'Gi0/0', 'neighbor': 'iosv-1'}) => changed=false
ansible_loop_var: item
item:
local_intf: Gi0/0
neighbor: iosv-1
msg: All assertions passed
ok: [iosv-2] => (item={'local_intf': 'Gi0/0', 'neighbor': 'iosv-0'}) => changed=false
ansible_loop_var: item
item:
local_intf: Gi0/0
neighbor: iosv-0
msg: All assertions passed
ok: [iosv-1] => (item={'local_intf': 'Gi0/0', 'neighbor': 'iosv-0'}) => changed=false
ansible_loop_var: item
item:
local_intf: Gi0/0
neighbor: iosv-0
msg: All assertions passed
ok: [iosv-0] => (item={'local_intf': 'Gi0/1', 'neighbor': 'iosv-2'}) => changed=false
ansible_loop_var: item
item:
local_intf: Gi0/1
neighbor: iosv-2
msg: All assertions passed
ok: [iosv-1] => (item={'local_intf': 'Gi0/1', 'neighbor': 'iosv-2'}) => changed=false
ansible_loop_var: item
item:
local_intf: Gi0/1
neighbor: iosv-2
msg: All assertions passed
ok: [iosv-2] => (item={'local_intf': 'Gi0/1', 'neighbor': 'iosv-1'}) => changed=false
ansible_loop_var: item
item:
local_intf: Gi0/1
neighbor: iosv-1
msg: All assertions passed
META: ran handlers
META: ran handlers
PLAY RECAP ************************************************************************************************
iosv-0 : ok=3 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
iosv-1 : ok=3 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
iosv-2 : ok=3 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Я запустил эту книгу с некоторой подробностью, чтобы показать, что возвращает каждая задача, и формат наших проанализированных данных.
Если мы внимательно посмотрим на вывод первой задачи, мы увидим под parsedключом, а также установив fact ( lldp_neighbors), что у нас есть структурированные данные от запуска сырого вывода через Genie.
Вторая задача показывает цикл для каждого хоста и itemего использование во время цикла. Если вы посмотрите на нашу книгу, мы используем local_intfи neighborдля наших утверждений из нашей approved_neighborsпеременной.
Резюме
Мы преобразовали данные с помощью настраиваемого плагина фильтра, но мы могли бы легко скорректировать факты и окончательные утверждения, чтобы они соответствовали выходным данным, полученным от Genie. Также важно показать возможность использования единой книги воспроизведения с использованием любого синтаксического анализатора для выполнения рабочих утверждений. Если бы мы были в производстве, мы могли бы заставить convert_dataнастраиваемый плагин фильтра переводить несколько различных форматов парсера в формат, независимый от парсера.
Для краткости, вот наш treeрезультат, чтобы показать вам, как выглядит структура папок при использовании настраиваемого плагина фильтра.
❯ tree
.
├── ansible.cfg
├── filter_plugins
│ └── custom_filters.py
├── group_vars
│ ├── all
│ │ └── all.yml
│ └── ios.yml
├── host_vars
│ ├── iosv-0.yml
│ ├── iosv-1.yml
│ └── iosv-2.yml
├── inventory
└── pb.validate.neighbors.yml
Наконец, содержимое файла custom_filters.py.
# -*- coding: utf-8 -*-
from __future__ import absolute_import, division, print_function
__metaclass__ = type
import re
def convert_genie_data(data):
intfs = []
for k,v in data['interfaces'].items():
intf_name = "Gi" + re.search(r'\d/\d', k).group(0)
intf_dict = {}
intf_dict['local_interface'] = intf_name
neighbor_intf = list(v['port_id'].keys())[0]
intf_dict['neighbor'] = list(v['port_id'][neighbor_intf]['neighbors'].keys())[0]
intfs.append(intf_dict)
return intfs
class FilterModule:
def filters(self):
filters = {
'convert_data': convert_genie_data,
}
return filters
Надеюсь, вам понравился этот пост в блоге, и вы немного больше понимаете о парсерах Genie и о том, как использовать их с помощью Ansible.