Есть несколько уровней инфраструктуры, и каждый из них имеет уязвимое место.
Первый уровень – это кластерные серверы, на которые приходится вся ваша рабочая нагрузка. Следующими уровнями являются кластеры и контейнеры. Наша цель – минимизировать участки, уязвимые к атаке.
Для начала убедитесь, что ваш кластер развернут в частной сети, а трафик поступает с load balancer и сервисов ingress. Не открывайте такие порты как SSH или RDP, старайтесь использовать SSM или вообще ничего, поскольку Kubernetes почти не нужна базовая система конфигураций. Кроме того, используя службы управления Kubernetes, вам даже не нужно беспокоиться о начальных настройках. Вы будете просто управлять операторами.
Непривилегированные пользователи (rootless)
Dockerfile-alpine
FROM alpine: 3.12 ,
# Create user and set ownership and permissions as required
RUN adduser - D myuser && chown - R myuser / myapp - data
COPY myapp / myapp
USER myuser
ENTRYPOINT ["/myapp"]
По умолчанию многие контейнерные службы работают как привилегированный пользователь root. В то же время программы, выполняемые внутри контейнера в качестве root, не нуждаются в привилегированном исполнении. Предотвращение использования root пользователя с помощью non-root или rootless контейнеров поможет снизить шансы скомпрометировать контейнер.
Неизменные контейнерные файловые системы
read-only-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
name: web
spec:
containers:
- command: [ "sleep" ]
args: ["999"]
image: ubuntu:latest
name: web
securityContext:
readOnlyRootFilesystem: true
volumeMounts:
- mountPath: /writeable/location/here
name: volName
volumes:
- emptyDir: {}
name:volName
Защита от создания файлов, загрузки скриптов и модификации программ в контейнере. Однако эти ограничения также влияют на законные контейнерные программы и могут привести к сбоям. Чтобы избежать повреждения законных программ, вы можете подключить вторичные файловые системы чтения/записи для определенных каталогов, где приложения требуют write-доступа.
Без shell, cat, grep, less, tail, echo и т.д.
Dockerfile
# Start by Building the application.
FROM golang: 1.13 -buster as build
WORKDIR /go/src/app
ADD . /go/src/app
RUN go get -d -v ./ ...
RUN go Build -o /go/bin/app
# Now copy it в наше base image.
FROM gcr.io/distroless/base-debian10
COPY --from=build /go/bin/app /
CMD [ "/app" ]
«Distoless» изображения содержат только ваше приложение и его зависимости во время выполнения. Они не имеют менеджеров пакетов, shell оболочек или любых других программ, которые вы ожидали бы найти в стандартном дистрибутиве Linux.
Меньше значит лучше
Сосредоточьтесь на меньшем объеме данных, хранящихся внутри контейнера. Вы должны хранить только свои программы, без исходного кода и build зависимости.
# Start by building the application.,
FROM golang: 1.13 -buster as build
WORKDIR /go/src/app
ADD . /go/src/app
RUN go get -d -v ./ ...
RUN go Build -o /go/bin/app
# Now copy it в наше base image.
FROM gcr.io/distroless/base-debian10
COPY --from=build /go/bin/app /
CMD [ "/app" ]
Секреты
a-
Video: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
Секреты Kubernetes, которые растут по мере жизни самой аппликации, используются для передачи конфиденциальной информации, например паролей или токенов, к событиям аппликации.
Вы можете хранить тип секрет в Kubernetes API, монтировать их как файлы или просто объявлять как переменную среды. Также есть операторы, например, Bitnami Sealed Secret, которые помогают зашифровать содержимое секрета и позволяют отправить конференционные данные в репозиторий. Даже публично.
Сканируйте Docker контейнеры
Хорошая новость заключается в том, что Docker и Snyk недавно объединились, чтобы обеспечить лучшее сканирование уязвимостей контейнеров. Что это значит для вас? Теперь Snyk интегрирован с Docker Hub для сканирования официальных изображений. Кроме того, Docker интегрировал сканирование Snyk прямо в клиенты Docker. Это означает, что теперь вы можете интегрировать его в одну команду для сканирования контейнеров в CI.
Конечно, вы можете использовать другие провайдеры, например Quay. Но они требуют большей интеграции и конфигурации. Кроме того, такие службы как Docker hub, AWS ECR, Quay, обеспечивают сканирование изображения после того, как вы отправили контейнер в Docker registry. Но пока вы будете исправлять эти уязвимости, контейнер, возможно, уже будет использоваться на нескольких средах и в том числе на продакшени.
Также существует несколько служб, которые можно развернуть, например, docker-bench-security. Они будут выполнять сканирование вашего кластера Kubernetes. Впрочем, это может быть лишним, ведь у нас есть Pod Security Policy, которая будет охватывать большинство наших мер безопасности, о чем мы поговорим ниже.
Безопасность Kubernetes
Первый вопрос, который мы должны задать, работая с Kubernetes, это «как я могу установить системные операторы и проектные аппликации в Kubernetes стекластере?» Почему бы не использовать инструменты CLI? Да это возможно. Но не обязательно означает, что это верный путь. Все workloads должны быть структурированы как пакеты и развернуты с определенной гибкостью. Для этого у нас есть Helm.
Helm помогает развертывать те же файлы YALM, но с шаблонизацией, как с переменными и условиями. Кроме того, он имеет историю ревизий, что позволяет восстановить ту или иную версию. Другими словами, Helm сделает вашу жизнь легче. Кроме того, почти все услуги предоставляют свои собственные Helm чарты, которые вы можете установить в один клик. Это так же просто, как установка пакетов в Linux.
Существует два подхода к автоматизированному и безопасному развертыванию Helm черт: push-based и pull-based.
Push-based подход – это то, что я люблю называть классическим подходом. Мы все его знаем, потому что используем каждый день. Скажем, вам нужно выстроить процесс CI/CD. Вы выбрали систему CI; вы создаете и отправляете артефакт, а затем запускаете развертывание непосредственно из CI. Это самый простой способ, и он имеет значительные преимущества, такие как обратная связь.
В нем тоже есть подводные камни. Во-первых, вы должны предоставить доступ к кластеру с CI, который обычно содержит права администратора. Во-вторых, состояние приложения может быть изменено с момента последнего выпуска, или кто-то может изменить конфигурации, и ваш CI будет сломлен. Таким образом, имея доступ администратора, CI может легко использовать, изменять или удалять другие ресурсы. Чтобы избежать этого, мы можем использовать другой подход.
Pull-based подход, также известный как GitOps, основанный на операторе, работающем внутри кластера. Он отслеживает изменения в хранилище и применяет автоматически. Поскольку оператор имеет доступ к репозиторию, нам не нужно предоставлять системе CI доступ к кластеру.
Преимущество использования этого подхода заключается в том, что у вас всегда есть источник истины (SSOT — Single Source of Truth ). Более того, оператор заметит любые изменения, внесенные вручную, и восстановит их в состояние репозитория, поэтому мы никогда не столкнемся со смещением конфигурации. Есть два pull-based инструменты: Flux и ArgoCD. Давайте поговорим об ArgoCD.
kind: Application
metadata:
name: bookinfo
namespace: argocd
spec:
destination:
namespace: bookinfo
server: https://kubernetes.default.svc
project: default
source:
path: applications/bookinfo
repoURL: git@github.com:sqerison/gitops-demo-kubernetes-workloads.git
targetRevision: main
syncPolicy:
automated:
prune: true
selfHeal: true
kind: AppProject
metadata:
name: bookinfo
namespace: argocd
spec:
destinations:
- namespace: '*'
server: '*'
clusterResourceWhitelist:
- group : '*'
kind: '*'
sourceRepos:
- git @github .com:sqerison / gitops - demo - kubernetes - workloads.git
- git @github .com:sqerison / gitops - demo - bookinfo - app.git
ArgoCD это оператор который и отвечает за pull-based подход и следует GitOps принципам. Основная его роль, это менеджмент ресурсов и их обновление при получении изменений из репозитория. ArgoCD работает с двумя основными ресурсами: Application и AppProject.
Application описывает сам ресурс, то есть аппликацию, которую нужно установить. Это может быть helm чарт, или обычные YAML файлы, будь то Kustomize ресурсы. Также мы указываем к какому проекту (AppProject) относится эта аппликация. И еще несколько других опций.
AppProject обеспечивают логическую группировку приложений, что полезно, когда Argo CD используется несколькими командами. Он имеет несколько функций, например, ограничить то, что может быть развернуто, ограничить типы объектов, которые могут или не могут быть развернуты, например, RBAC, CRD, DaemonSets, Network Policy и т.д. При создании аппликации мы можем выбрать, в рамках какого проекта она будет существовать, и какие доступы она получит и не позволит выйти за рамки дозволенного.
kind: AppProject
metadata:
name: bookinfo
namespace: argocd
spec:
destinations:
- namespace: '*'
server: '*'
clusterResourceWhitelist:
- group : '*'
kind: '*'
sourceRepos:
- git @github .com:sqerison / gitops - demo - kubernetes - workloads.git
- git @github .com:sqerison / gitops - demo - bookinfo - app.git
Pod Security Policy
В начале статьи упоминались non-root контейнеры, read-only файловые системы и другие docker практики, как передача сокета docker, или использование сети системы (—net=host).
С помощью PSP мы можем ввести и не допустить выполнения событий, если эти требования не будут удовлетворены.
psp-non-privileged.yaml
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: example
spec:
privileged: false # Вы не можете пользоваться pods!
# Занимающиеся fills в некоторых необходимых полях.
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
runAsUser:
rule: MustRunAsNonRoot
fsGroup:
rule: RunAsAny
volumes:
- '*'
Вот обычный пример, для чего можно применить PSP. Запрещает запуск контейнеров в привилегированном режиме (privileged: false) и запрещает работу под пользователем root (MustRunAsNonRoot). Важно! Для того что правила PSP ресурса вступили в силу, их нужно авторизовать с помощью RBAC.
Из-за сложности инженеры часто не используют этот ресурс, потому что вместе с политиками, вам нужно позаботиться о других конфигурациях, ломая голову, как и где их использовать. Вот почему PSP функционал в ближайшее время станет устаревшим.
Но PSP – не единственное, что мы можем использовать для обеспечения функций безопасности. У нас есть Open Policy Agent.
Open Policy Agent
Агент Open Policy, в сущности, является Gatekeeper-ом. Это оператор, который оценивает запросы к контроллеру допуска (admission controller), чтобы определить, соответствуют ли они правилам.
С помощью этого инструмента мы можем расширить контроль над создаваемыми ресурсами. Мы можем контролировать такие вещи как labels, requests и limits. Это важно, когда вы хотите масштабировать ваше приложение. Мы также можем ограничить список репозиториев docker, разрешив только корпоративные или AWS ECR. С помощью Gatekeeper вы можете ограничить любую опцию или аргумент во всех ресурсах Kubernetes.
Но, как и любой мощный инструмент, у него достаточно сложный синтаксис политики. В сущности, это язык REGO. Позвольте показать вам пример.
opa-k8spspprivilegedcontainer-ct.yaml
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8spspprivilegedcontainer
spec:
crd:
spec:
name:
kind:
K8sPSPPrivilegedContainer
- target: admission.k8s.gatekeeper.sh
rego: |
package k8spspprivileged
violation[{"msg": msg, "details": {}}] {
c := input_containers[_]
c.securityContext.privileged
msg := sprintf( "Privileged container is not allowed: %v, securityContext: %v" , [c.name, c.securityContext])
}
input_containers[c] {
c := input.review.object.spec.containers[_]
}
input_containers[c] {
c := input.review.object.spec.initContainers[_]
}
Это политика для ограничения docker репозиториев с типом ConstraintTemplate. Я не знаю, как писать на REGO. Это только пример, который я нашел в библиотеке, предоставленной Gatekeeper на GitHub. Итак, эта конфигурация – это просто шаблон, и аргументы для этого приведены в следующем примере.
opa-k8sallowedrepos-inuse.yaml
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sAllowedRepos
metadata:
name: repo-is-openpolicyagent
spec:
match:
kinds:
- apiGroups: [ "" ]
kinds: "
"
- "default"
parameters:
repos:
- "openpolicyagent/"
- "quay.io/"
- "<aws_account>.dkr.ecr.<region>.amazonaws.com/"
Как только вы создадите шаблон, Gatekeeper на его основе создаст CRD, на который вы сможете ссылаться, описывая какие именно репозитории вы хотите разрешить и для каких namespace-ов это применить. Мы применяем эту политику к модулям и namespace-ам по умолчанию, но вы можете и самостоятельно определить некоторые namespace-ы. В конце концов у нас есть список реестров, которым мы хотим доверять. Самое трудное – это написать шаблоны, которые вообще можно погуглить, а остальное не сложное.
Network Policies
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
namespace: default
name: deny-from-other-namespaces
spec:
podSelector:
matchLabels:
ingress:
- from:
- podSelector: {}
Network Policies гораздо проще в использовании по сравнению с Gatekeeper-ом. Как вы знаете, namespace-ы в Kubernetes не изолированы друг от друга, и любой под может общаться с любым другим подом. Это не очень хорошо, особенно если у вас есть сервисы с конфиденциальными данными или мониторингом, которые должны иметь доступ только к порту метрик. Кроме того, если у вас есть кластер с несколькими клиентами, содержащий аппликации от разных клиентов, вы должны быть уверены, что они не будут взаимодействовать друг с другом.
В этом примере можно увидеть, как разрешить трафик из других namespace-ов на основе лейбов. И да, если вы хотите проэкспериментировать сетью, вы можете запустить под в тестовом namespace-е с меткой prod, и трафик будет разрешен. Но это не очень критично. В крайнем случае всегда можно обратиться к Gatekeeper-a и указать, какие именно лейбы должны присутствовать в данном namespace-е.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: web-allow-prod
spec:
podSelector:
matchLabels:
app: web
ingress:
- from:
- namespaceSelector:
matchLabels:
purpose: production
Чтобы Network Policies работали, вам нужно установить поддерживающий их сетевой плагин (CNI). Calico – хороший кандидат. AWS EKS имеет собственный сетевой плагин, и, в крайнем случае, вы можете использовать Security Groups для просмотра и управления правилами AWS консоли.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: api-allow-5000
spec:
podSelector:
matchLabels:
app: apiserver
ingress:
- ports:
- port: 5000
from:
- podSelector:
matchLabels:
role: monitoring
Последний пример – ограничения по порту. Если быть точным, разрешите трафик только в порт с метриками, к которому будет доступна система мониторинга.
Еще одно замечание по AWS CNI. В случае использования Custom Networking Network Policies потеряют свою силу. Поэтому вы должны выбирать, какая система политик вам больше подходит.
Кроме того, есть еще Mesh система Istio, которая имеет свои политики. Она работает на седьмом уровне OSI, и позволяет управлять трафиком более гибко. Но Istio – достаточно широкая тема, поэтому мы сегодня не будем о ней говорить.
Секреты
Всем сейчас интересно, как мы можем безопасно доставить конфиденциальную информацию в кластер, не беспокоясь о потере или раскрытии. Хорошим кандидатом для управления вашими секретами является Bitnami Sealed Secrets. Вам просто нужно зашифровать секрет с помощью ключа шифрования и результатом шифрования уже будет готовый ресурс, который уже можно разворачивать в кластере.
Другой альтернативой является GitCrypt, который шифрует файлы с помощью GPG ключей и может быть расшифрован только другим ключом, которые были предварительно добавлены. Это не самый лучший вариант для секретов Kubernetes, но хороший для других конфиденциальных данных, таких как частные ключи или kubeconfig.
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
annotations:
sealedsecrets.bitnami.com/cluster-wide: "true"
creationTimestamp: null
name: demo-secret
spec:
encryptedData:
api-key: AgCK+iL6mZX6woqKiYQPWeELNt4/JrpaiwLR75d24OnshhsNveGB7CqGF1dr+rAxal4gr+d4No4Q+uAQgUizgLnY2IdWvAKVh/3miCgPW8SO8p8BOxpD8U1qBgJBb74M8rPbvxh47L0y2iSymSa4wdf4zcyju5CvoWnnB0Qbsx6lNzGMDnt6rjjzje3Su7ktrj4qnmX6BhRnukGmw+bErT31DzVWDrgrlcd2eQFuAflysckJv7wdIZXKSZwAWHAJzipUcNbG+O+UHJwia7RXwef9F2Ruebnl2jXH5/7iCV+83NLivdl0aW2TzLGOLR1NMG63NtN3T95Qfisame2QkYCBmYRCCCn3iwwxzDXDymAFE9/RqnnIPzhA/K0YayPZnLInoO3pTVxF1DL+RnmWRojUOwoO5ZkY++Behzq7nn9nRrEC+u/aDk2CXwJe9WbHwVgznKM7N6v4IUlcQz93VhRUbDetnWhA3TnD+HDsc85z0hvFp8c2U4giqRL4CnXHQIfBG63hLHoAogWOH8I+paVId180DWFpwjsAsKXVbESUa2ORL7LmuiDg1qKLoVFxiEEVJmnYPv5F8P1XMvJPW6L6QRQnJqj/ntyRSyEKnNh3umRTBoJzfXNDhsDXMPMu0leuYN1D+arx6IHBCKPexevE53iE7JK05bj/Oq8ujCOJRyv6TqjX4gQM3+kgXmi8rnCYB1CJg6lvhH1+pw==
template:
data: null
metadata:
annotations:
sealedsecrets.bitnami.com/cluster-wide: "true"
creationTimestamp: null
name: demo-secret
Здесь вы можете увидеть пример Sealed Secrets. Как видите, значение зашифровано. И как только вы развернете этот файл в кластере, оператор Bitnami Sealed Secrets. преобразует и расшифрует этот файл в обычный секрет. Как этот.
Как видите, теперь наш Sealed Secret – это обычный секрет. А помните ArgoCD? Как уже упоминалось ранее, вы можете легко предоставить доступ к ArgoCD разработчикам и другим инженерам. Но не забудьте убедиться, что у них доступ только на чтение.
Kubernetes Hardening
Теперь пора поговорить о самих компонентах кластера. Они также имеют свои уязвимые места и злоумышленники с радостью воспользуются ими в случаи неправильных конфигурации.
API Server
API Server является ядром Kubernetes. На некоторых ванильных и старых версиях кластеров, API-сервер работает не только через HTTPS, но и на незащищенном порту (HTTP), который не проверяет аутентификации и авторизации. Обязательно убедитесь, что вы отключили незащищенные порты. Вы также можете попытаться отправить curl запрос на 8080 порт, чтобы проверить, получите ли ответ.
Etcd
Etcd похож на базу данных, которая хранит информацию о кластере и секретах кластера. Это важный компонент, и каждый, кто может писать в etcd может эффективно контролировать ваш Kubernetes кластер. Даже простое чтение содержимого etcd может легко дать полезные подсказки потенциальному злоумышленнику. Сервер etcd должен быть сконфигурирован так, чтобы доверять только сертификатам, которые предназначены API-серверам. Таким образом, он будет доступен только для проверенных компонентов в кластере.
Kubelet
Кубелет. Это агент, получающий инструкции, что делать и где делать. В основном отвечает за планирование ваших аппликаций в кластере. Проверьте наличие анонимного доступа и правильного режима авторизации, и вы будете в безопасности.
Kubernetes dashboard
Kubernetes панель. Эту систему лучше отключить полностью, поскольку у нас есть другие инструменты, которые могут помочь нам понять статус кластера. Как, например, ArgoCD. Вы увидите только ресурсы, созданные Argo, но это хорошо, поскольку обычно проблемы возникают из-за аппликации и ресурсы проекта, а сам кластер достаточно стабильным.
Другие вспомогательные инструменты
Это еще не все. У меня есть несколько инструментов, которые помогут в поиске уязвимых мест.
Kubescape
Чтобы запустить этот инструмент, достаточно выполнить две команды. Одну – для загрузки скрипта, а другую – для его выполнения. В результате вы получите список уязвимостей и неправильных конфигураций с итогом и общей оценкой в конце. Помните рекомендации по усилению Kubernetes? Этот инструмент проверит их для вас. Кроме того, Kubescape использует базы данных, которые соответственно обновляются для обнаружения новых уязвимостей.
Kube-bench
Он почти такой же, как Kubescape, за исключением того, что он выполняется внутри кластера и может быть развернут как Cronjob для регулярного сканирования.
Kubesec
Простой плагин для сканирования модулей Kubernetes.
Kubeaudit
Имеет подобные функции, но используется для обнаружения неисправности (debugging) и создает хороший список с примерами, которые помогут устранить их.
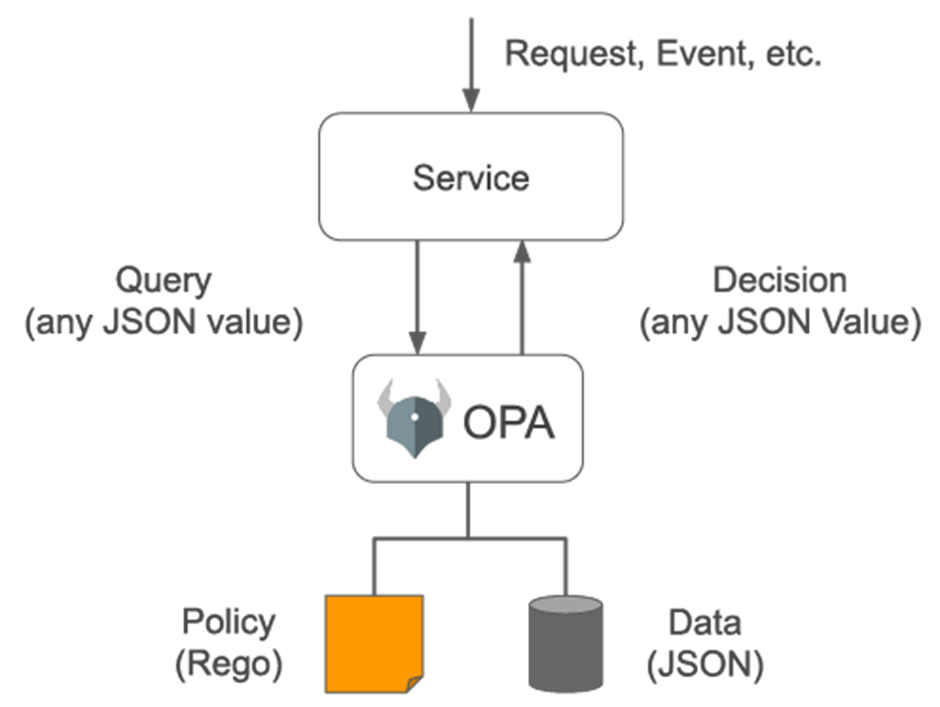 Схема работы OPA
Схема работы OPA