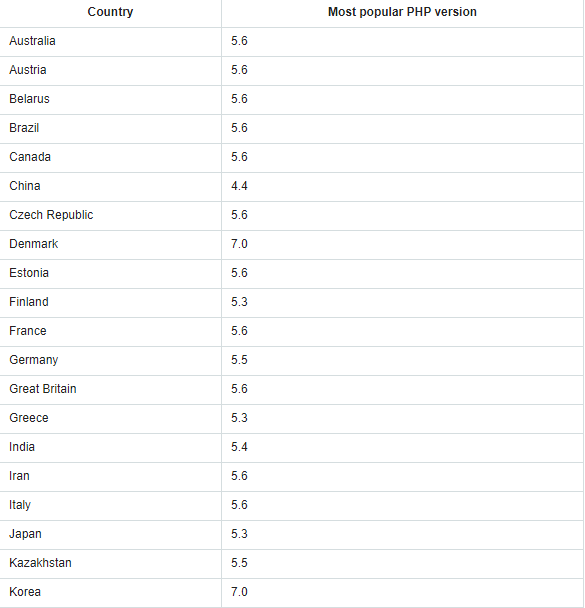
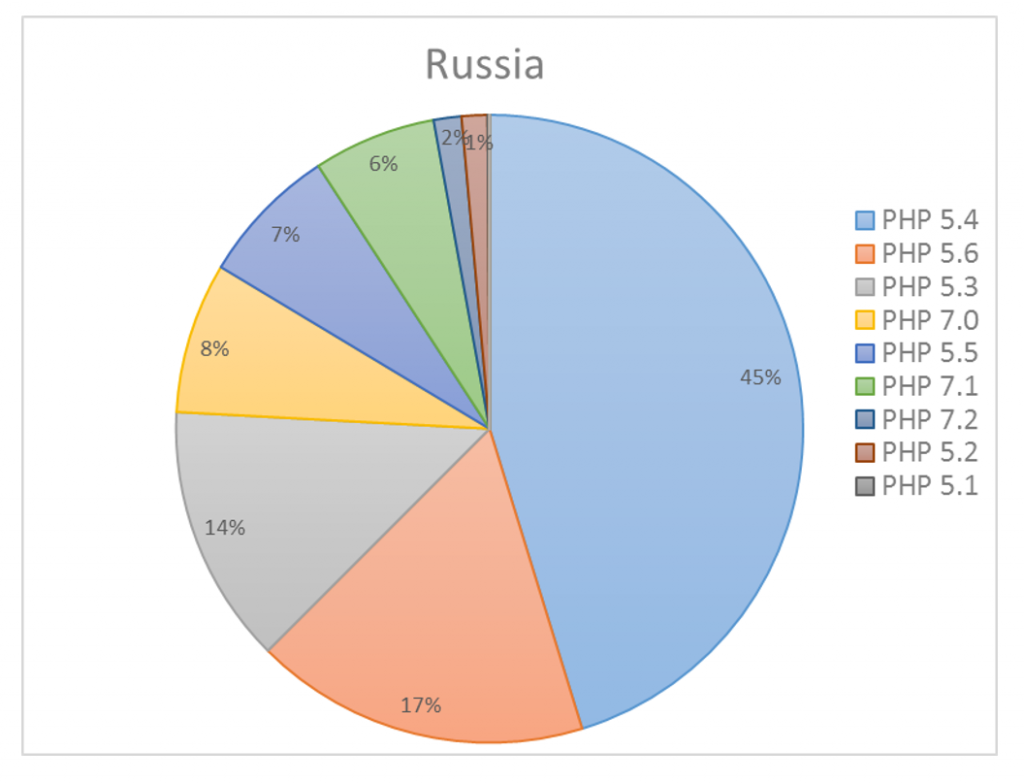
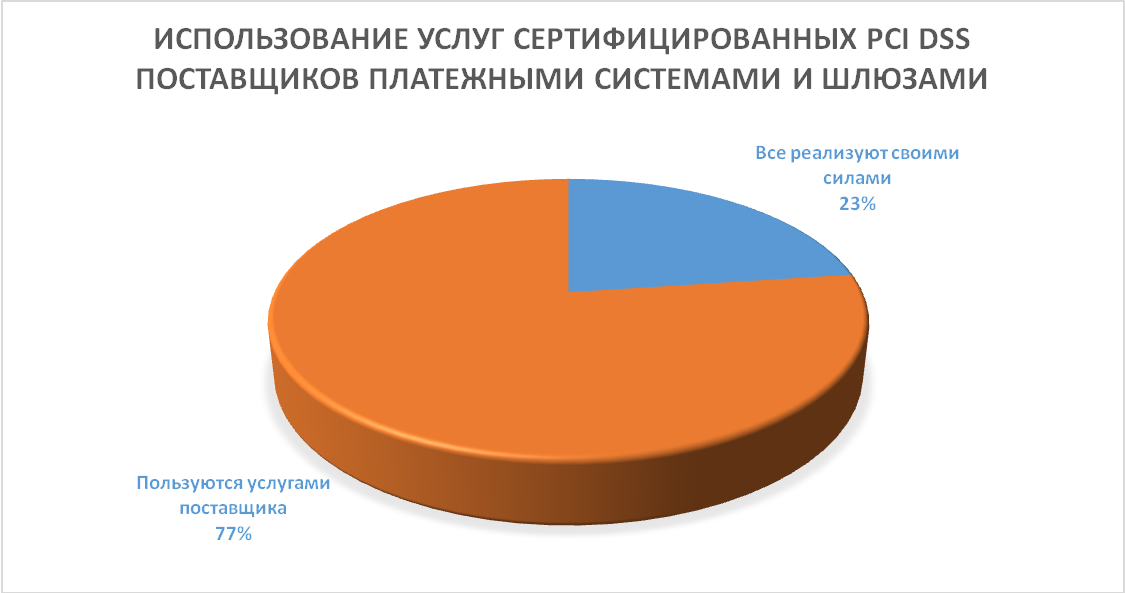
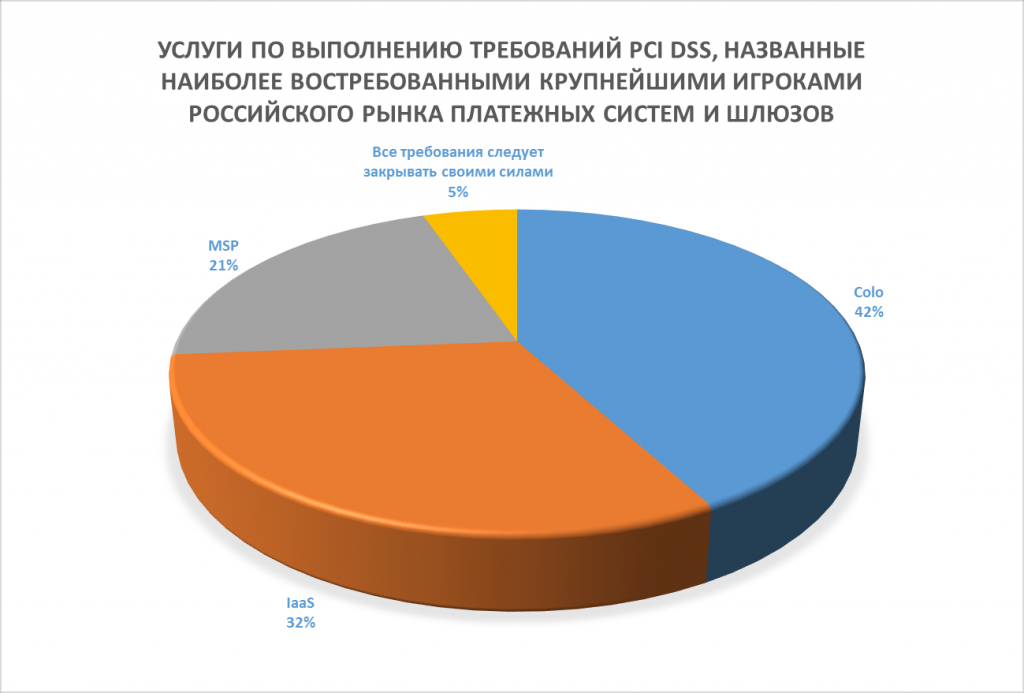
Ни одно предложение в истории Microsoft не находило такого отклика, как Office 365. Клиенты верят, что платформа не только удовлетворит их профессиональные нужды, но и обеспечит надежную защиту и управление критически важными для бизнеса информационными ресурсами. Безопасность в Office 365 достигается благодаря непрерывной работе в области мониторинга, обслуживания, совершенствования, подготовки отчетов и проверки.
Microsoft стремится показать, что ваши данные в Office 365 остаются вашими; их никогда не будут анализировать для рекламных кампаний и к вашим данным никогда не будут обращаться иначе как с целью предоставления «облачных» услуг для организации офисной работы. Когда вы оформляете подписку на использование Office 365, вам предъявляется ряд предупреждений о нормативных требованиях с описанием способов управления.
Конечно, на различных веб-сайтах и в документах Microsoft содержится самая полная информация, но часто она представлена в разнородных форматах и разбросана по многим сайтам, что затрудняет изучение важных тем. Мы считаем, что было бы полезно дать единый, исчерпывающий обзор мер защиты данных, применяемых на платформе Office 365, который послужит надежным основанием для разработки стратегии управления данными в компании.
Структура этой статьи очень проста: мы приводим подробное описание различных функций безопасности, соответствия требованиям, администрирования и управления, реализованных в Office 365. Для всех тем избран единый порядок представления:
- Описание каждой функции управления или защиты данных.
- Объяснение ее предназначения и способов применения.
- Источники дополнительной информации.
Мы уверены, что такой материал будет незаменимым ресурсом для администраторов Office 365 и специалистов по безопасности. Компания Microsoft приложила немало усилий, чтобы по возможности уменьшить опасения относительно безопасности данных в Office 365.
Обязательно обратите внимание на центр управления безопасностью Office 365 Trust Center — в нем вы найдете подробные объяснения для всех рассмотренных в данной статье тем. На сайте своевременно отражаются все изменения в стандартах, применимых к Office 365, приводятся сведения о новых мерах безопасности и ссылки на многие национальные и международные сертификаты, выданные «облачной» платформе.
Цель предлагаемого руководства — дать обзор этих материалов, чтобы помочь читателям разобраться в подходе Microsoft к защите целостности ваших данных и улучшению качества служб, предоставляемых Office 365. Приведенную в статье информацию можно разделить на четыре категории: безопасность, соответствие требованиям, администрирование и управление.
Если на вас возложены какие-либо обязанности по техническому развитию или обслуживанию платформы Office 365, если вы – владелец компании, обеспокоенный тем, как ваши данные обрабатываются в Office 365, или если вы пытаетесь узнать больше об административных функциях платформы, то это руководство для вас.
Как Office 365 обеспечивает безопасность
Теперь, после обзора тем, которые будут затронуты в данной статье, рассмотрим каждую из возможностей системы безопасности, соответствия требованиям, администрирования и управления, реализованных в платформе Office 365, начиная с безопасности данных.
В основе Office 365 лежат одни из самых надежно защищенных центров обработки данных в мире, соответствующие составленным в компании Microsoft требованиям жизненного цикла разработки защищенных приложений Security Development Lifecycle (SDL). Многие методики складывались десятилетиями, и в течение этого времени Microsoft вела собственные разработки корпоративного программного обеспечения, так что начиная с конца 1990-х эти усилия охватывали многочисленные веб-службы.
Платформа Office 365 располагает пользовательскими и административными функциями управления корпоративного уровня, которые дают организациям возможность масштабировать среды, обеспечивая гарантию безопасности на всех уровнях (физическом, логическом и уровне данных) и соответствия отраслевым стандартам.
Microsoft постоянно повышает уровень безопасности платформы Office 365, от сканирования портов и периметра до регулярного аудита действий и доступа оператора или администратора. Если вы хотите быть в курсе шагов, предпринимаемых Microsoft для защиты данных, советуем обратить внимание на сайт Office 365 Roadmap (https://products. office.com/en-US/business/office-365-roadmap) и время от времени посещать его, чтобы следить за свежими обновлениями.
Физическая безопасность
В этом разделе речь пойдет об управлении доступом к системам и данным. Microsoft обеспечивает круглосуточную безопасность всего оборудования центров обработки данных, в том числе мульти-факторную проверку подлинности всех систем и биометрическое сканирование для физического доступа. Все системы внутренней сети отделяются от внешней.
Кроме того, вследствие разделения ролей даже сотрудники с физическим доступом к системам не могут определить местоположение конкретных данных клиента. Рабочие процедуры в центре обработки данных гарантируют, что оборудование и системы обновляются и оптимизируются, неисправные накопители и устройства размагничиваются и уничтожаются. Вы можете спать спокойно, зная, что оборудование, в котором хранятся ваши данные, защищено в одном из самых надежных центров обработки данных в мире.
Логическая безопасность
Это защита программного обеспечения и платформы с использованием проверок подлинности, паролей, уровней разрешения и других мер, благодаря которым только определенные люди получат доступ к вашим данным.
Microsoft предоставляет клиентам полный контроль над их данными в редких случаях, когда Microsoft необходим доступ к данным, чтобы разрешить конфликт (защищенное хранилище Office 365 Customer Lockbox). Office 365 обеспечивает упреждающее управление угрозами, сканирование портов и периметра и точное управление процессами из одобренного списка на сервере, защищая от вредоносного кода и несанкционированного доступа.
Безопасность данных
Это защита конфиденциальности и целостности данных от стихийных бедствий, порчи системы или отказа оборудования и противоправных действий пользователя. Шифрование неактивных и пересылаемых данных защищает их как на серверах, так и в устройствах хранения или при передаче между пользователем и Microsoft.
В дополнение к борьбе с текущими угрозами, мониторингу безопасности и предотвращению любого вмешательства в работу системы или порчи данных, Office 365 предоставляет подробные соглашения об уровне обслуживания (SLA) для аварийного восстановления и обеспечения непрерывности бизнес-процессов, помогая удовлетворить все требования к безопасности.
Каким образом Office 365 управляет соответствием требованиям?
Платформа Office 365 поддерживает клиентов во всем мире, опираясь на различные стандарты и нормативы, определяющие обработку информационных ресурсов. Microsoft постоянно расширяет список поддерживаемых стандартов соответствия требованиям и безопасности.
Один из ключевых принципов доверия к Office 365 — соответствие требованиям. В коммерческих организациях действуют нормативы и политики, которым необходимо соответствовать для ведения бизнеса в различных областях. Эти политики могут представлять собой сочетание внешних нормативных требований, зависящих от отрасли и географического положения, и внутренних политик компаний.
Office 365 располагает встроенными возможностями и пользовательскими элементами управления, которые помогут добиться соответствия как различным отраслевым нормативам, так и внутренним требованиям и идти в ногу с непрерывно меняющимися современными стандартами и нормативными актами.
Чтобы закрепить эти достижения и продолжать завоевывать доверие пользователей, Microsoft проходит независимые аудиторские проверки, подтверждающие соответствие всем политикам и процедурам для безопасности, соответствия требованиям и конфиденциальности.
К основным аспектам встроенных возможностей соответствия требованиям относится независимый аудит, удостоверяющий соответствие Office 365 многим мировым отраслевым стандартам и сертификатам.
В Office 365 используется инфраструктура управления, в которой реализован стратегический подход к внедрению обширных функций контроля соответствия стандартам, которые в свою очередь удовлетворяют различным отраслевым нормативам. Office 365 поддерживает более 600 функций управления, которые позволяют Microsoft обеспечить соответствие сложным стандартам и предложить контракты клиентам из регулируемых отраслей, такие как ISO 27001, типовые регламенты ЕС, соглашения о деловых партнерах HIPAA Business Associate Agreements и FISMA/FedRAMP.
Кроме того, Microsoft использует исчерпывающее соглашение об обработке данных для решения проблем конфиденциальности и безопасности, касающихся данных клиентов, помогая клиентам обеспечить соответствие местным нормативным актам. Дополнительные сведения по этой теме можно получить в статье с вопросами и ответами по обеспечению соответствия требованиям нормативных документов Microsoft (https://www.microsoft.com/online/ legal/v2/en-us/MOS_PTC_ Regulatory_Comp.htm).
Чтобы предоставить клиентам возможность наиболее полного контроля над соответствием требованиям в Office 365, Microsoft разработала три полезные службы.
- Предотвращение потери данных (DLP). DLP — стратегия и инструментарий, которые помогают администраторам управлять потоком конфиденциальной или критически важной информации вне корпоративной сети. С помощью DLP администраторы могут настраивать политики в зависимости от нужд своей компании в сфере соответствия требованиям, чтобы уменьшить вероятность случайного разглашения финансовой информации, персональных данных (PH) или иных важных сведений об интеллектуальной собственности. Подсказки политики DLP размещают уведомления непосредственно в электронной почте пользователя, предупреждая его о потенциальных опасностях перед отправкой сообщения электронной почты. Эти уведомления могут также использоваться как образовательное средство для ознакомления сотрудников с корпоративными политиками соответствия требованиям.
- Центр eDiscovery. Обнаружение электронных данных (eDiscovery) — процесс, с помощью которого можно вести поиск, обнаруживать и защищать электронные записи с целью их использования при разрешении юридических вопросов. Эти возможности Office 365 позволяют искать информацию на сайтах SharePoint Online, почтовых ящиках Exchange Online, учетных записях One Drive для бизнеса или во всех перечисленных хранилищах сразу. Центр eDiscovery позволяет создавать «досье», которые обеспечивают пространство взаимодействия для сбора ключевых элементов, необходимых для формирования доказательной основы. С помощью eDiscovery в Office 365 можно обнаруживать любую информацию, сохраненную в данной среде, в том числе архивированные сообщения электронной почты.
- Управление записями сообщений Messaging Records. Management (MRM) — внутренняя технология хранения данных в Office 365. Параметры настройки позволяют применять политики управления записями как к содержимому Exchange Online, так и к SharePoint, чтобы указать информацию, которую следует сохранить, и информацию, потребности в которой больше нет. Ведение журнала и подготовка отчетов аудита позволяют отслеживать все что угодно, от действий администратора до доступа к документам и их удаления. Предусмотрено много функций ведения журнала и подготовки отчетов, которые могут быть настроены в соответствии с конкретными нуждами. Сочетание архивации электронной почты и механизма eDiscovery может облегчить задачу пользователям и администраторам за счет сокращения объема работы по организации папки “Входящие” и автоматического применения политики хранения данных на основе типа используемой информации. Дополнительное преимущество архивации заключается в том, что вашим пользователям не приходится сортировать свои почтовые сообщения в независимых архивных файлах на локальных системах, которые могут располагаться за пределами вашего ИТ-подразделения.
Мы можем помочь перенести в облако корпоративную ИТ инфраструктуру и внедрить Office 365. Свяжитесь с нами office@itfb.com.ua