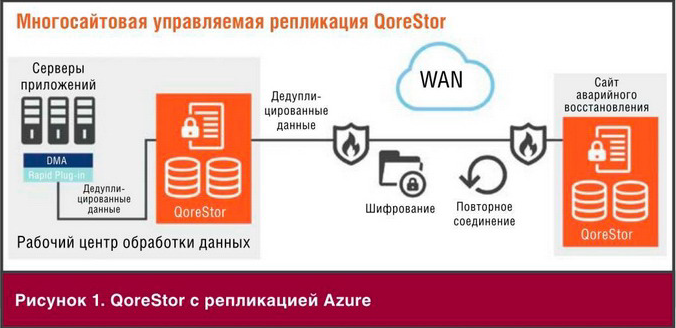
Успех современного бизнеса чем дальше, тем больше зависит от способности реагировать на изменения. Новые игроки нарушают баланс на рынке, а технологии в корне меняют ожидания потребителей, и компаниям приходится корректировать свои планы. Благодаря современным программным архитектурам и процессам компании могут лучше приспосабливаться к переменам и побеждать в конкурентной борьбе.
В новой архитектурной инфраструктуре. именуемой гибкой интеграцией, соединены три важных архитектурных компонента: контейнеры, распределенная интеграция и программные интерфейсы (API). Данная инфраструктура определяет, как перечисленные ключевые компоненты обеспечивают гибкость и эффективность новых процессов, происходящих внутри компании, принося ей конкурентные преимущества.
В таких отраслях, как, например, туризм и гостиничное дело, произошли важные перемены — предоставляются новые возможности, а потребители иначе взаимодействуют с поставщиками услуг. Глубокие изменения охватывают и другие крупные отрасли, от финансового сектора до госучреждений. Их подстегивают разрабатываемые технологии и новый взгляд на взаимодействие между компаниями и потребителем. Приспосабливаясь к вызовам современного мира, компаниям приходится радикально перестраивать свои ИТ-технологии, чтобы предложить новые услуги.
Для доставки программного обеспечения на современных скоростях компаниям нужен фундамент гибкой инфраструктуры. В данном случае в термин Agile вкладывается более традиционный смысл, чем обычно при разработке программ. Agile означает «гибкий», «способный быстро двигаться».До настоящего времени гибкие методики были направлены на разработку программного обеспечения в стремлении усовершенствовать и упростить процесс создания программ. Методы DevOps представляли собой попытку перенести эти методики на развертывание приложений.
Однако область действия методологии DevOps ограничена и охватывает в основном новые приложения, самостоятельно разрабатываемые компаниями. Гибкость инфраструктуры распространяется дальше и создает среду, которая охватывает все ИТ-системы, в том числе устаревшие программы. Гибкая инфраструктура — подход, который нивелирует сложность существующих систем, различных типов данных, потоков данных и позволяет объединить их. В этом суть проблемы интеграции.
Компания, которая может в одночасье изменить цепы или быстро начать выпускать новые продукты, имеет огромное преимущество перед конкурентом, использующим трехмесячную многоэтапную процедуру с последовательностью ручных операций проверки.Мы называем это гибкой интеграцией. Интеграция не является частью инфраструктуры — это концептуальный подход к инфаструктуре, который охватывает данные и приложения наряду с оборудованием и платформами. Совмещая технологии интеграции с гибкостью и технологиям и DevOps, можно создать платформу, которая позволяет рабочим группам вносить изменения так быстро, ка к того требует рынок.
Конец планирования
«Планирования, каким мы его знаем, больше не существует, — заявил в своем выступлении на конференции Red Hat Summit Джим Уайтхерст, главный управляющий Red Hat.— Планирование в малоизученной среде неэффективно». В стремительно развивающейся бизнес-срсде неспособность лавировать, своевременно корректируя свои действия, может обойтись чрезвычайно дорого. Это означает, что чем меньше информации вы имеете или чем менее стабильна среда, тем ниже ценность планов.
Планирование инфраструктуры обычно требует долгосрочного подхода. Попытка составить многолетний план порой подавляет способность к реагированию на резкую смену ситуации на рынке . Конец планирования, о котором говорил Джим Уайтхерст, означает возможность планировать быстрее, а затем воплощать свои планы. Сокращается время существования планов и самой среды, в которой реализуются новые проекты .
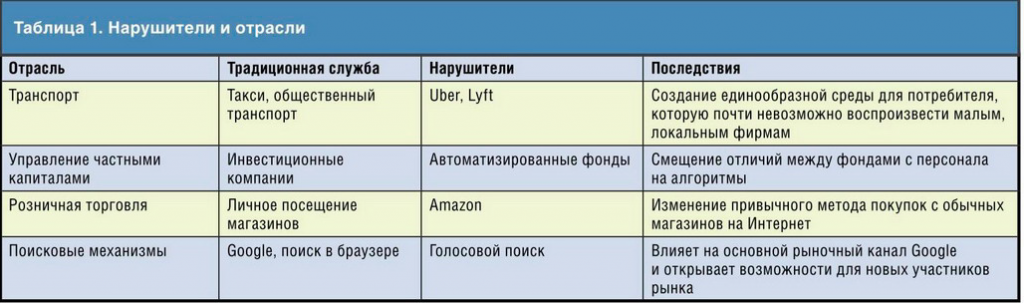
Рабочим группам, привычным к полугодовым или даже двухлетним циклам разработки, непросто приспособиться к быстрым переменам. Проблема усугубляется, когда традиционно структурированные компании бывают вынуждены конкурировать с начинающим и компаниями , которые используют совершенно новые подходы. Очевидные примеры — N etflix и Blockbuster или Uber и традиционное такси, но подрыв устоявшегося порядка молодыми компаниям и прослеживается с начала информационного века, с Amazon в 1993 году и персональных компьютеров в 1980-х (таблица 1).
Преимущество начинающих компаний в свободе выбирать свою инфраструктуру, организовы вать рабочие группы , приложения, архитектуру и даже процессы развертывания.
У них не только есть новаторская идея — они могут реализовывать свои замыслы, поскольку их не сдерживает устаревшая инфраструктура. Они могут быть гибкими.
Помимо возможности построить что-то новое, такие компании создают системы, готовые к переменам. Почти любой компонент системы у них может быть обновлен или заменен в зависимости от меняющихся потребностей рынка. По мере того как возраст стартапов увеличивается, способность к адаптации некоторых из них падает, но лучшие компании всеми силами стараются не потерять способности адаптироваться к переменам.
Что необходимо для успеха
Для эффективной работы в быстро меняющейся среде вся ИТ -инфраструктура должна функционировать гибко. Изменения могут происходить на двух уровнях:
- организационная и культурная поддержка гибких процессов — от проектирования архитектуры до связи между рабочими группами;
- техническая инфраструктура , которая позволяет быстро обновлять, добавлять и удалять функциональные возможности.
Технические и культурные изменения не обеспечивают гибкость. О ни создают фундамент для гибкости. Марти Каган , менеджер продукта компании eBay, облагает каждый проект « налогом » — некоторое время и ресурсы из каждого обычного проекта выделяются для работы над новыми инфраструктурным и проектам и. Таким образом, новые проекты и новации становятся приоритетными.
Инфраструктура гибкости
Многочисленные новые технологии часто не способствуют созданию гибкой инфраструктуры , поскольку различные группы двигаются в разных направлениях, исследуя возможности для совершенствования. Без согласованного набора целей верхнего уровня трудно определить, какой набор новых функциональных возможностей принесет наибольшие выгоды для компании в целом.
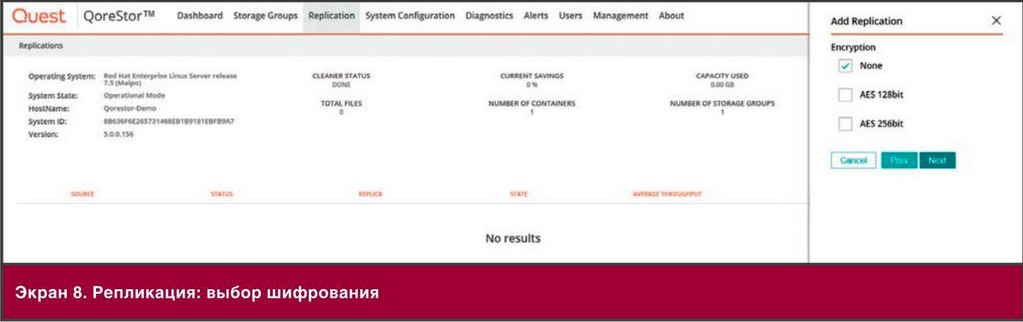
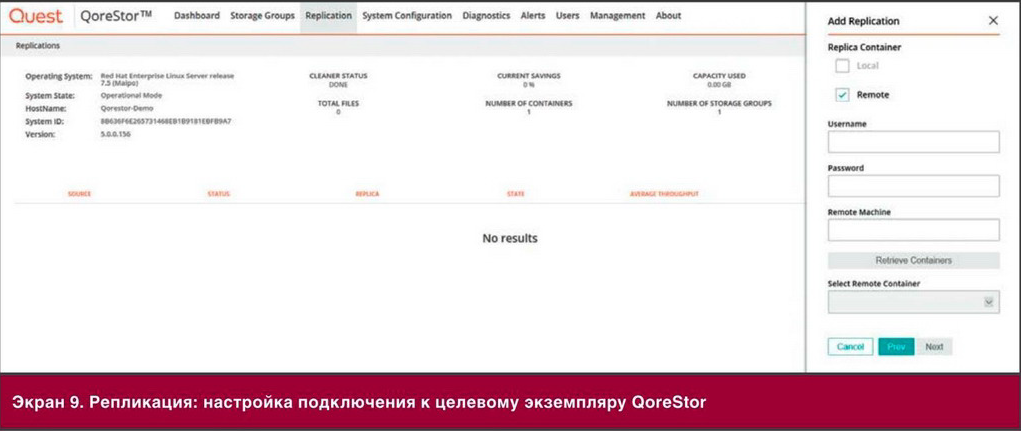
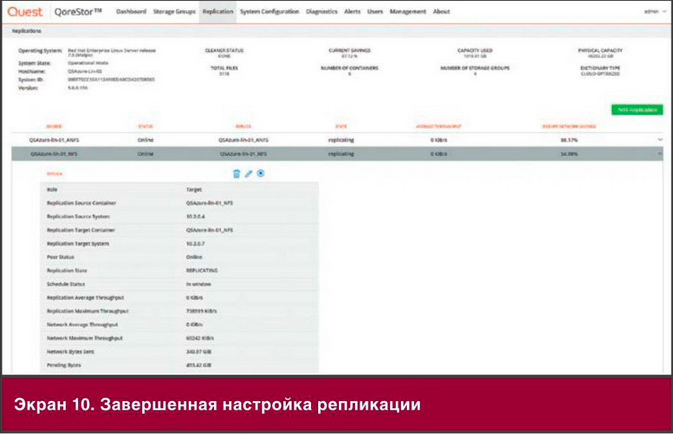
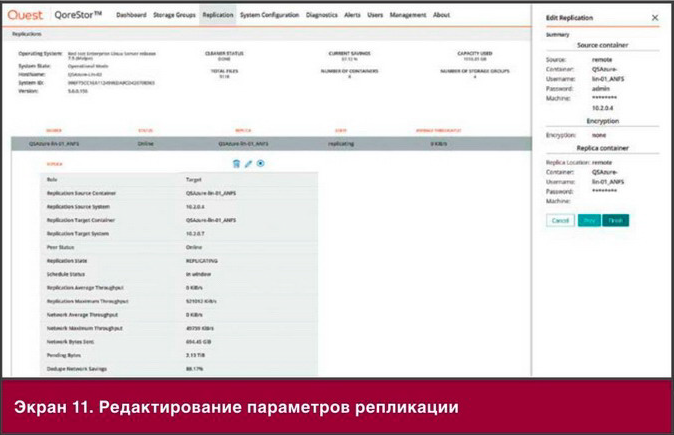
Три столпа гибкой интеграции
Подход к гибкой интеграции базируется на трех основных технологиях:
- Распределенная интеграция. Несколько десятков высокоуровневых шаблонов интеграции отражают потоки данных и рабочих процессов на предприятии. Если эти шаблоны интеграции развернуты в контейнерах, то их можно развернуть в нужных масштабах и там, где необходимо для конкретных приложений и рабочих групп. Это архитектура распределенной интеграции, отличная от традиционной архитектуры централизованной интеграции. Благодаря ей отдельные рабочие группы могут гибко определять и развертывать требуемые шаблоны интеграции.
- API-интерфейсы. Стабильные, хорошо управляемые A P I-интерфейсы имеют решающее значение для взаимодействия между рабочими группам и, разработчиками и специалистами по эксплуатации. A P I-интерфейсы заключают важнейшие активы в стабильные, повторно используемые интерфейсы, позволяя этим интерфейсам служить строительными блоками для многократного применения в масштабах компании, с партнерами и клиентами. API-интерфейсы можно размешать вместе с контейнерами в различных средах, что позволяет пользователям взаимодействовать с разными наборами API-интерфейсов.
- Контейнеры. Это базовая платформа развертывания как для API, так и для технологий распределенной интеграции. Контейнеры позволяют развернуть нужную службу в определенной среде простым и единообразным для разработки, тестирования и обслуживания способом. Поскольку контейнеры являются доминирующей платформой для среди микро служб DcvOps, их использование в качестве платформы интеграции обеспечивает более прозрачное и тесное сотрудничество между группами разработчиков и специалистами по инфраструктуре.
Благодаря трем перечисленны м технологиям И Т-инф раструктура становится более гибкой, поскольку каждая из них повышает уровень абстракции, на котором различные рабочие группы могут действовать совместно. Использование контейнерной платформы с АРІ-интерфейсами и распределенными интеграционными компонентами абстрагирует реализацию интеграции от самой интеграции.
Гибкость рабочих групп повышается, так как API-интерфейсы и шаблоны распределенной интеграции упаковывают конкретные активы на понятном уровне и при этом нет необходимости изменять базовую инфраструктуру. Каждая из названных технологий в отдельности обеспечивает значительную гибкость при решении конкретных задач интеграции. При совместном использовании они обеспечивают мультипликативный эффект. Преимущества технологии увеличиваются в сочетании с методиками DcvOps, особенно процессами автоматизации и развертывания.
Распределенная интеграция
Одна из крупнейших проблем современных ИТ-систем состоит в необходимости объединять приложения в масштабах всей компании. Трудности интеграции приводят к созданию все более сложных центров интеграции. Эти центры, часто реализуемые как корпоративные сервисные шины (ESB), превратились в чрезвычайно сложные узкие места, не поддающиеся быстрым изменениям.
Распределенная интеграция позволяет достичь во многом тех же технических целей, что и предшествующие поколения ESB, но способом, более удобным для адаптации рабочими группам и. Как и ESB, технология распределенной интеграции обеспечивает преобразование, маршрутизацию, анализ, обработку ошибок и рассылку предупреждений.
Различие заключается в архитектуре интеграции.
В архитектуре распределенной интеграции каждая точка интеграции рассматривается как отдельное и уникальное развертывание, а нс часть более крупного, централизованного приложения интеграции. Затем интеграцию можно поместить в контейнер и развертывать локально для конкретного проекта или рабочей группы, не влияя на другие интеграции, развернутые в компании.
Распределенный подход обеспечивает необходимую гибкость проектов. В нем используется та же цепочка инструментов, которая применяется рабочими группами DevOps, благодаря базовой контейнерной платформе, что увеличивает способность рабочих групп управлять своими интеграциями с помощью собственных инструментов и расписания. В сущности, интеграция рассматривается как микрослужба, что ускоряет процессы разработки и выпуска.
Критическое значение имеет согласование процессов и инструментов разработчика. Главная особенность распределенной интеграции состоит в том, что это не централизованная программная инфраструктура, разработанная и управляемая специализированной группой пользователей водном подразделении и развернутая отдельно от процесса разработки программного обеспечения. Благодаря распределенности архитектуры интеграции, с обшей платформой и инструментарием, она доступна всем разработчикам на уровне проекта и поддерживает компактные развертывания всегда и везде, где необходима интеграция.
Чтобы использовать ESB, рабочей группе приходится в течение всего жизненного цикла применять инструменты ESB наряду с любыми инструментами, используемыми в средах разработки и эксплуатации (таблица 2).

Результатом становятся неудобство, потери в эффективности и ошибки при эксплуатации.
Обмен сообщениями способствует интеграции
Архитектурно точки интеграции при распределенной интеграции рассматриваются как микрослужбы. Их можно заключать в контейнеры, легко развертывать локально и часто обновлять выпуски. Технология интеграции должна поддерживать такого рода компактную архитектуру на основе микрослужб. С помощью, например. Red Hat Fuse пользователи могут рассматривать интеграции как программный код, пригодны й для запуска повсюду, втом числе в контейнере.
Кроме того, Fuse поставляется с Red Hat J Boss A M Q , чтобы обеспечить инфраструктуру обмена сообщениями. Мощная инфраструктура обмена сообщениями гарантирует эффективную марш рутизацию событий и данных между системами. Обмен сообщения ми — важный архитектурный инструмент для микрослужб, поскольку его асинхронная природа не требует зависимостей.
Такое сочетание интеграций и обмена сообщениями повышает общую производительность архитектуры интеграции благодаря более эффективной маршрутизации, поддержке многих языков и протоколов, асинхронным подключениям и усовершенствованному управлению данными.
Следим за тенденциями
Контейнеры применяются все чаще, но насколько и почему? Аналитики компании 451 Research прогнозируют рост рынка на 250%, но это объем затрачиваемых средств, а не развертывания. Оценить развертывания несколько сложнее. В результате опроса, выполненного компанией Bain по заказу Red Hat. выяснилось, что около 20% клиентов сегодня развертывают контейнеры в производственной среде и примерно столько же в средах разработки и тестирования, но более 30% оценивают контейнеры и выполняют проверку концепции.
Что означает «использовать контейнеры»? В Enterprisers Project обрисованы четыре различных варианта применения контейнеров: в качестве общей платформы разработки и развертывания; ка к «облачной» платформы или платформы микрослужб; в гибридном «облаке» и для инновационных проектов. От способа использования контейнеров зависит, как пользователь рассматривает их внедрение.
Идея гибкой интеграции заключается в создании инфраструктурной платформы, поддерживающей существующие операции. На платформе могут быть представлены все варианты реализации, но в своей основе она работает как фундамент для новых проектов и существующих служб.
Источник: журнал “Windows IT Pro/RE”