Сегмент ежедневно получает миллиарды событий от наших клиентов, и он уже расширился до десятков аккаунтов AWS. Увеличение количества аккаунтов необходимо для поддержки нашего GDPR и программ безопасности, но при этом стоимость получается высокой. Для продолжения плавного масштабирования мы инвестируем в инструмент разработки, чтобы работники могли ими пользоваться со многих аккаунтов, а также инвестируем в управление доступом работников к AWS при помощи терраформы и нашего поставщика identity.
Сегмент начался с единственного аккаунта AWS, а в прошлом году завершился наш переход к dev, stage, prod и ops аккаунтам. В течение последние нескольких месяцев мы увеличивались в среднем на один новый аккаунт AWS в неделю или два и планируем расширяться на командные и системные аккаунты. Наличие многих “микроаккаунтов” обеспечивает превосходную изоляцию безопасности между системами и преимущества надежности, ограничивая радиус уничтожения ограничений скорости AWS.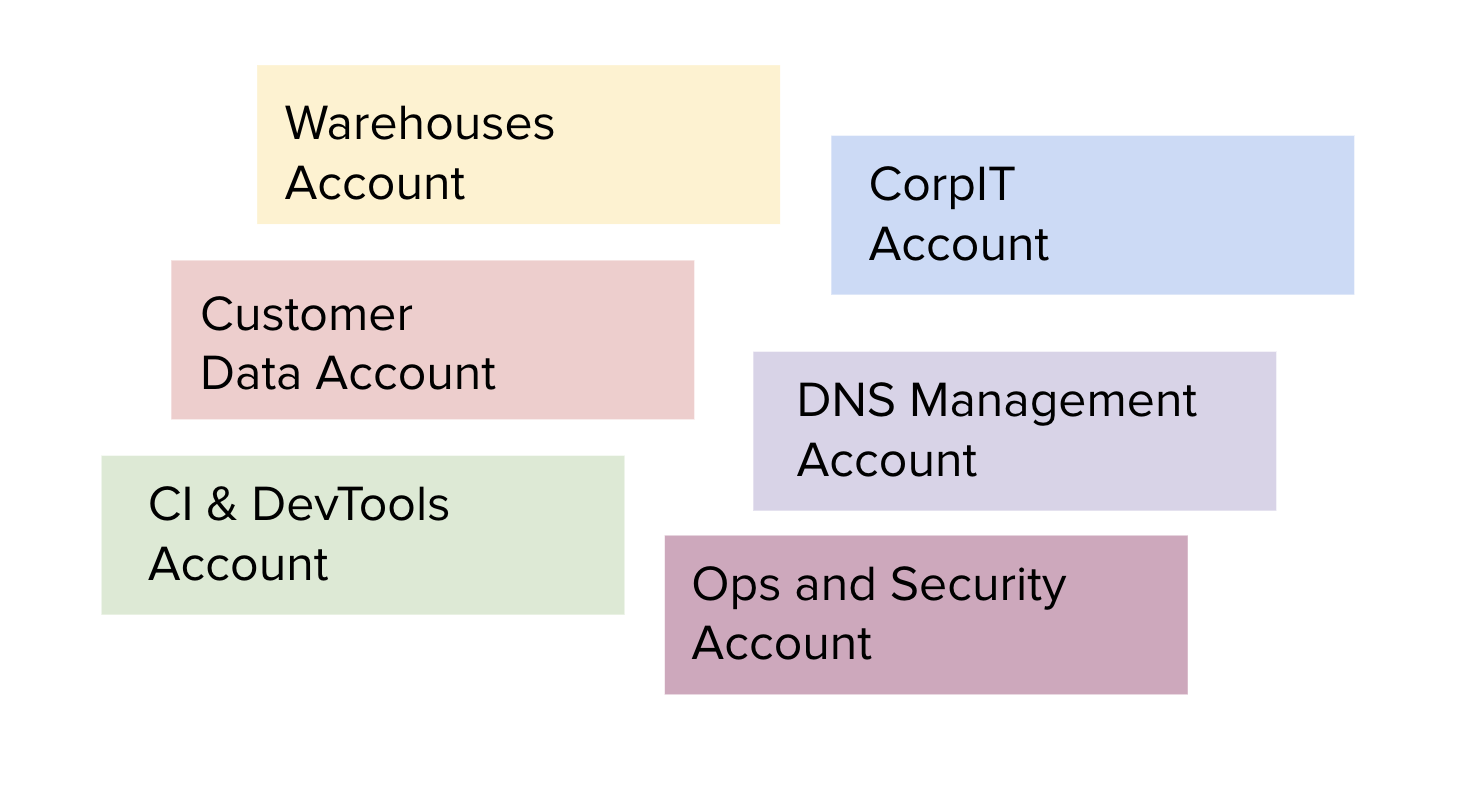
Когда в Сегменте было всего несколько учетных записей, работники входили в учетную запись ops AWS, используя собственные e-mail, пароль и 2FA символ. Потом работники присоединились к роли ops-admin в учетных записях dev, stage и prod, используя AssumeRole api.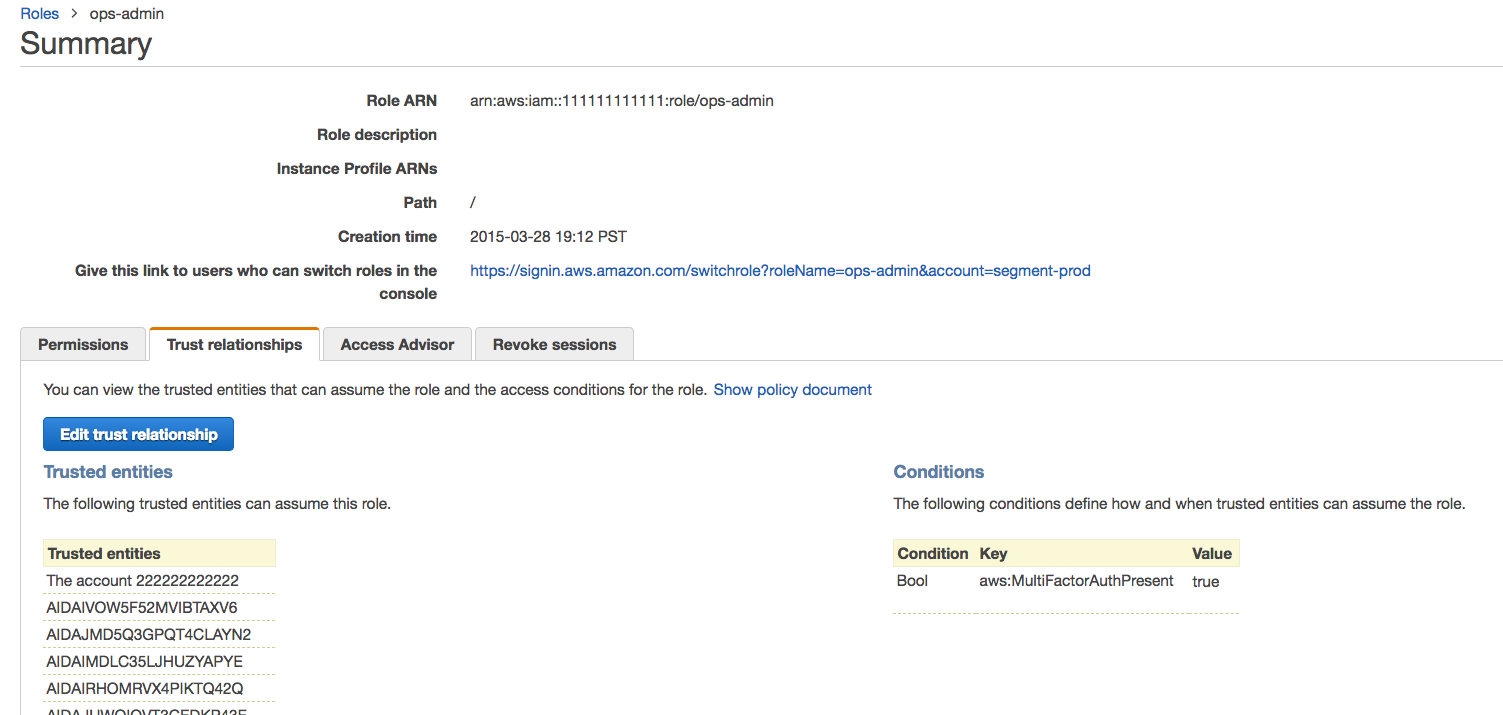
В данный момент в сегменте существуют десятки учетных записей AWS, но планируется создать еще больше! Для организации расширения нам нужен механизм контроля наших учетных записей, к которым у работников есть доступ, и разрешения работников на каждую учетную запись.
Нам также не нравится пользоваться ключами AWS API, когда в этом нет необходимости, поэтому мы перешли на системе, в которой у работников нет ключей. Вместо этого работники подключаются к AWS через нашего провайдера удостоверений. На данный момент у нас нет работников с ключами AWS, а также отсутствует необходимость в ключах и в будущем. Это уже большая победа в плане безопасности!
Разработка масштабируемой архитектуры IAM
В Сегменте используется Okta как провайдер удостоверений (identity), который обращался за справкой к их справочнику по интеграции по управлению аккаунтами AWS, но улучшился с небольшими изменениями для достижения лучшего UX работников. Интеграционное руководство рекомендует связывать провайдера удостоверений с каждой учетной записью AWS, но таким образом нарушается встроенность AWS в поддержку переключения учетных записей и это усложнило контроль того, к какой роли команда имеет доступ.
Вместо этого работники используют нашего провайдера удостоверений для связи с нашими ops аккаунтами, а затем используют простой базовый элемент assume-role API службы, чтобы связаться с каждой учетной записью, к которой у них есть доступ. При использовании нашего провайдера идентификационных данных, каждая команда имеет разную роль в нашей учетной записи хаба, кроме этого, роль каждой команды имеет доступ к разным ролям в каждой учетной записи. Это классическая осевая (англ. hub-and-spoke) архитектура.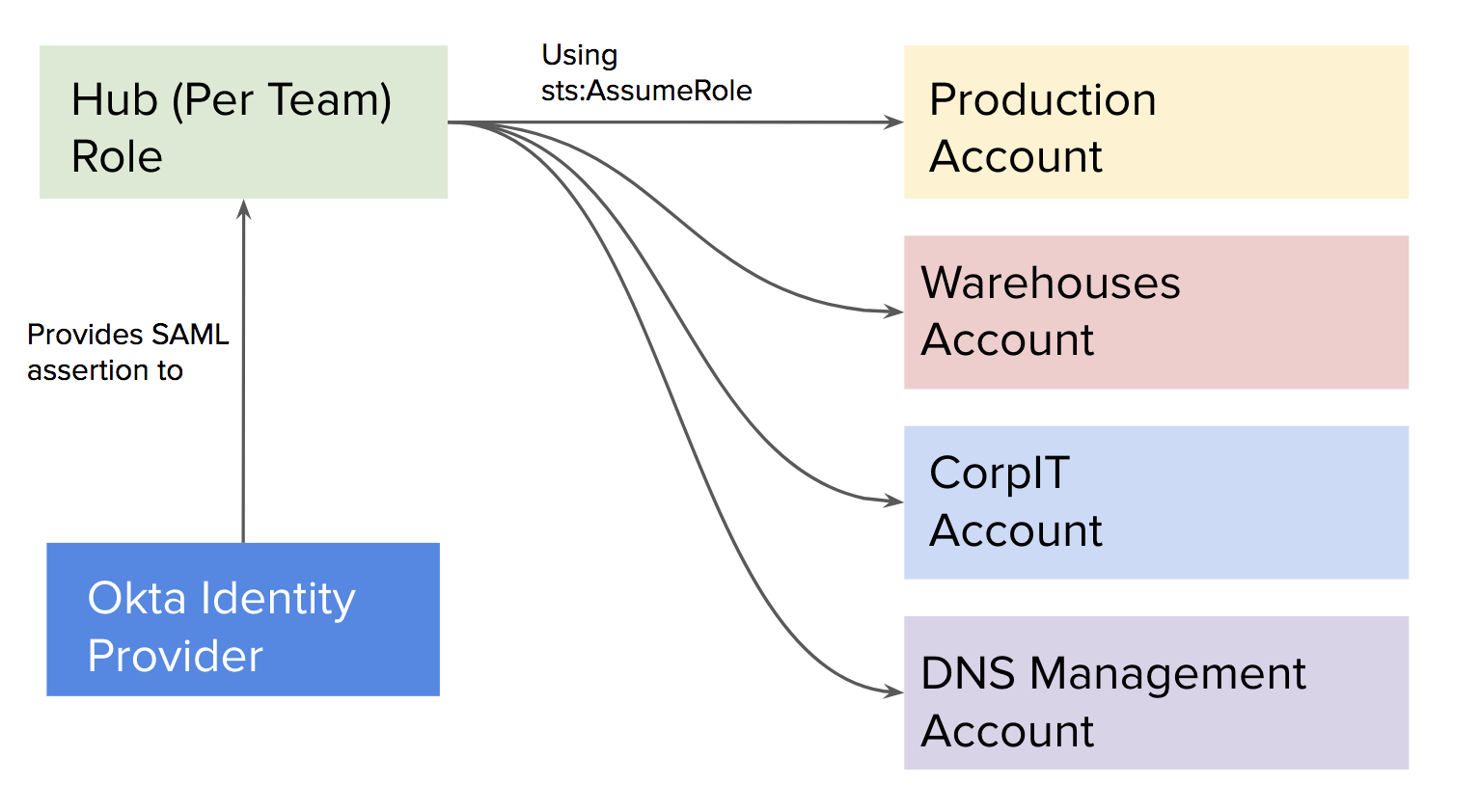
Для упрощения обслуживания осевой архитектуры мы создали модуль терраформ для создания роли в нашей разговорной учетной записи и отдельный модуль терраформы для создания роли в учетной записи хаба. Оба модуля просто создают роль и прикрепляют к ней ARN политику, являющуюся частью модуля ввода.
Единственно различие между этими модулями заключается в их доверительных отношениях. Ролевой модуль хаба дает доступ из провайдера идентификационных данных, в то время как разговорный модуль только дает доступ из учетной записи хаба. Ниже находится модуль, который мы используем для доступа к ролевому хабу из нашего провайдера идентификационных данных.
resource "aws_iam_role" "okta-role" {
name = "${var.name}"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "${var.idp_arn}"
},
"Action": "sts:AssumeRoleWithSAML",
"Condition": {
"StringEquals": {
"SAML:aud": "https://signin.aws.amazon.com/saml"
}
}
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "okta-attach" {
policy_arn = "${var.policy_arn}"
role = "${aws_iam_role.okta-role.name}"
}
Чтобы предоставить каждой команде детализированный доступ только к тем ресурсам, которые необходимы командам, мы создаем роль для каждой команды в учетной записи хаба, используя наш ролевой террафом модуль хаба. Эти роли большей частью содержат политики IAM для sts: AssumeRole в других учетных записях, но также возможно предоставить детализированный доступ в нашей роли хаба.
Одним конкретным и простым примером детализированной политики является роли нашей команды о финансовом планировании и анализе, при этом команда пристально следит за нашими расходами AWS. Наша FP&A команда имеет доступ к информации о счете и информации о нашем зарезервированном объеме.
module "fpa" {
source = "git@github.com:segmentio/terracode-access//modules/okta-role"
name = "fpa"
idp_arn = "${module.idp.idp_arn}"
policy_arn = "arn:aws:iam::aws:policy/job-function/Billing"
}
resource "aws_iam_policy" "fpa_reserved_policy" {
name = "fpa_reserved_policy"
description = "FP&A team needs ability to describe our reserved instances."
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"ec2:GetHostReservationPurchasePreview",
"ec2:DescribeReservedInstancesModifications",
"ec2:DescribeReservedInstances",
"ec2:DescribeHostReservations",
"ec2:DescribeReservedInstancesListings",
"ec2:GetReservedInstancesExchangeQuote",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeHostReservationOfferings",
"ec2:CreateReservedInstancesListing"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "fpa_reserved_attach" {
role = "fpa"
policy_arn = "${aws_iam_policy.fpa_reserved_policy.arn}"
}
Однако, у команды FP&A нет доступа к нашим разговорным учетным записям. Единственная команда, которой нужен полный доступ к большей части нашей архитектуры и всем нашим учетным записям, – это команда основы и надежности, которая принимает участие в развертыванию по необходимости. Мы предоставляем нашей базовой команде как ReadOnly роль, так и роль администратора во всех наших учетных записях.
После того, как роли для каждой команды созданы в учетной записи хаба, работники распределяются по группам, которые представляют свои команды в Okta, и каждая команда затем может быть назначена на связанную роль в учетной записи хаба.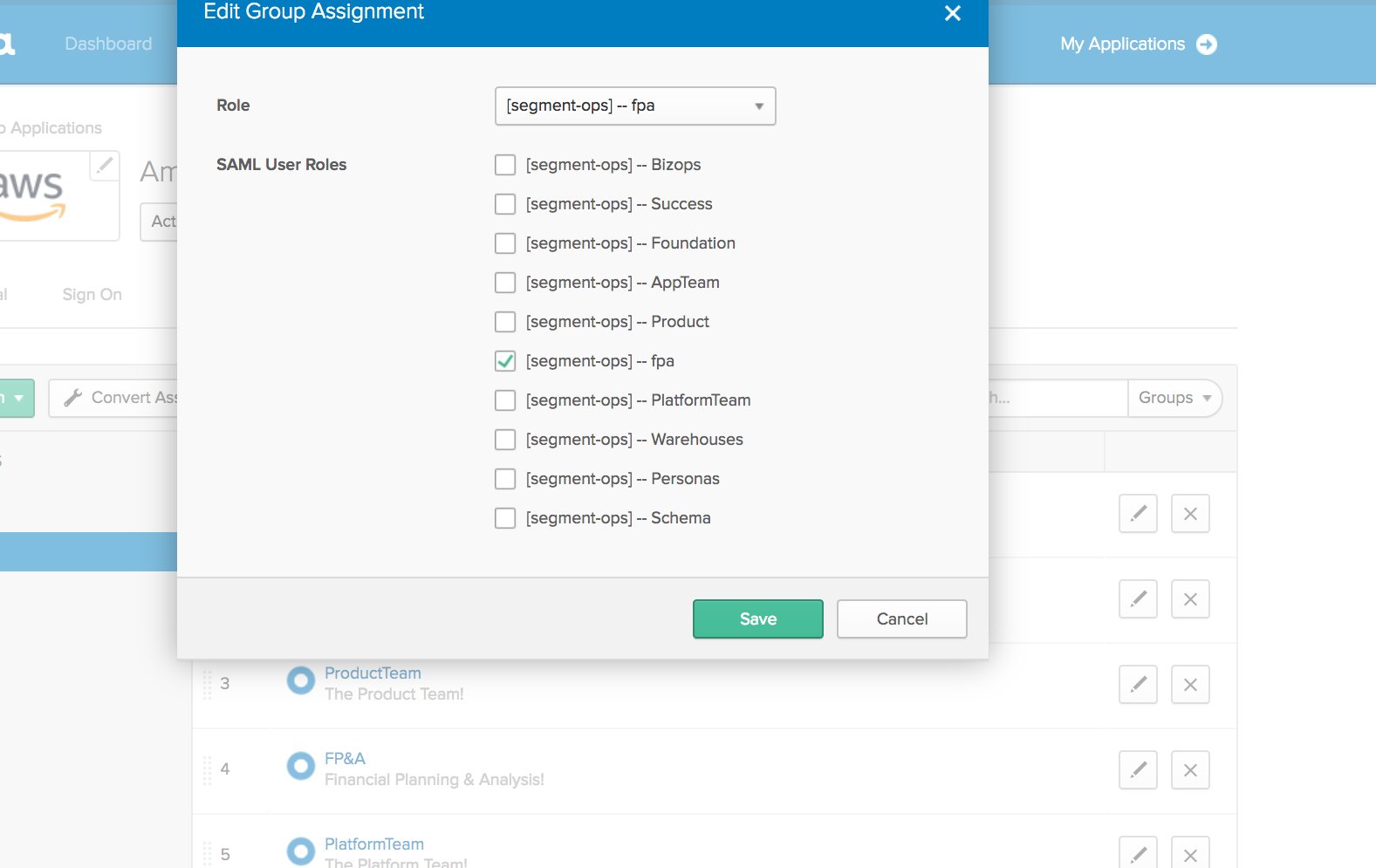
Okta позволяет каждой группе получить разные роли IAM в учетной записи хаба и при использовании их UI мы можем дать приложение “Amazon Web Services” команде FP&A и ограничить их доступ к роли fpa, которую мы для них создали в учетной записи хаба.
Выполнив все это, нам понадобились инструменты для того, чтобы предоставить своим работникам удивительный инженерный опыт. Хотя эта система достаточно безопасна, мы хотели, чтобы она была настолько же легко используемой и эффективной, как и установка только с рядом учетных записей AWS
Поддержание удобства пользования с aws-okta
Единственное, что было замечательно в нашей старой установке IAM это то, что каждый работник с доступом к AWS мог пользоваться AWS API с их локальных компьютеров при наличии хранилища. У каждого работника имя пользователя и пароль IAM, надежно хранимый в компьютерной связке ключей. Однако, доступ к AWS полностью через Okta – это значительная перемена в нашем старом направлении работы.
Наша команда оснащения приняла вызов и создала (близкое) понижение замены для aws-хранилища, которое наша команда инженеров использовала экстенсивно, названный aws-okta. aws-okta сейчас является открытым ресурсом и доступным на github.
Качество aws-okta является основной причиной того, что инженеры сегментов смогли беспрепятственно удалить свои учетные данные AWS. Работники могут выполнять команды при помощи полученных разрешений и ролей точно так же, как когда они использовали aws-хранилище.
$ aws-okta exec hub -- aws s3 ls s3://<some-bucket> 2018/02/08 15:40:22 Opening keychain /Users/ejcx/Library/Keychains/aws-okta.keychain INFO[0004] Sending push notification...
Для аутентификации с Okta, aws-okta нужно знать “id приложения” вашего Okta. Мы взяли на себя смелость на расширение файла ~/.aws/config ini, чтобы добавить необходимый id.
[okta] aws_saml_url = home/amazon_aws/uE2R4ro0Gat9VHg8xM5Y/111
Когда в сегменте было только несколько аккаунтов AWS и роль ops админа, все инженеры сегмента делили ~/.aws/config. Как только каждая команда получила доступ к разным аккаунтам и системам, нам понадобилась система для управления ~/.aws/config каждой команды. Нашей системе также нужен способ обновить доступ, который работники быстро получили при создании новых учетных записей и ролей.
Мы решили интегрировать данное решение близко к предшествующему методу, который Сегмент создал. Каждая настройка команды хранится в git repo, в которой находится dotfiles нашей компании. Каждая команда может инициализировать их конфигурацию aws при помощи нашего внутреннего инструмента, названного robo, который является инструментом для совместного использования полезных команд между сотрудниками.
$ SEGMENT_TEAM=foundation robo config.aws ✔ : Your old aws config has been backed up in /tmp/awsconfig-318c16acc2b25bed2eb699e611462744 ✔ : Your aws config was successfully updated. $ shasum ~/.aws/config c2734b78e470c51a26d8c98e178d4ec2ed1b1b06 /Users/ejcx/.aws/config $ SEGMENT_TEAM=platform robo aws.config ✔ : Your old aws config has been backed up in /tmp/awsconfig-d5688401634de0e8b2f48b11377d0749 ✔ : Your aws config was successfully updated. $ shasum ~/.aws/config 283053d6f5a23ca79f16c69856df340b631d3cdf /Users/ejcx/.aws/config
Это было только возможно добавить, потому что у всех инженеров Сегмента уже была переменная среды, названная SEGMENT_TEAM, которая обозначает команду, частью которой является инженер. Выполнение robo aws.config клонирует dotfiles repo, сохранит старый ~/.aws/config и инициализирует новую конфигурацию для их команды.
Закладки AWS были основным способом, которым инженеры перемещались по нашей среде, когда мы использовали меньше учетных записей. Когда мы избавились от роли опс-администратора, инженеры, войдя в систему закладки, прекратили работать. Кроме того, закладки AWS только поддерживают до пяти различных целей AssumeRole, и у нас теперь есть намного больше, чем пять учетных записей.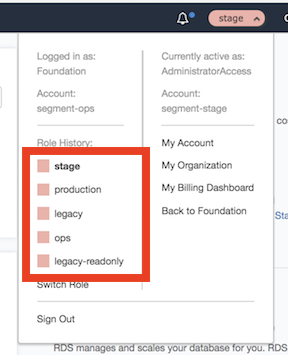
Чтобы поддерживать существование еще большего числа учетных записей, мы главным образом отказались от закладок и вместо этого гарантировали, что aws-okta поддерживает инженеров, которым часто было нужно переключать учетные записи AWS. Наше предыдущее использование aws-хранилища означало, что многие из нас были знакомы с командой входа в систему aws-хранилища. Мы узнали, что добавление команды входа в систему к aws-okta помогло инженерам, которые часто сменяли аккаунты.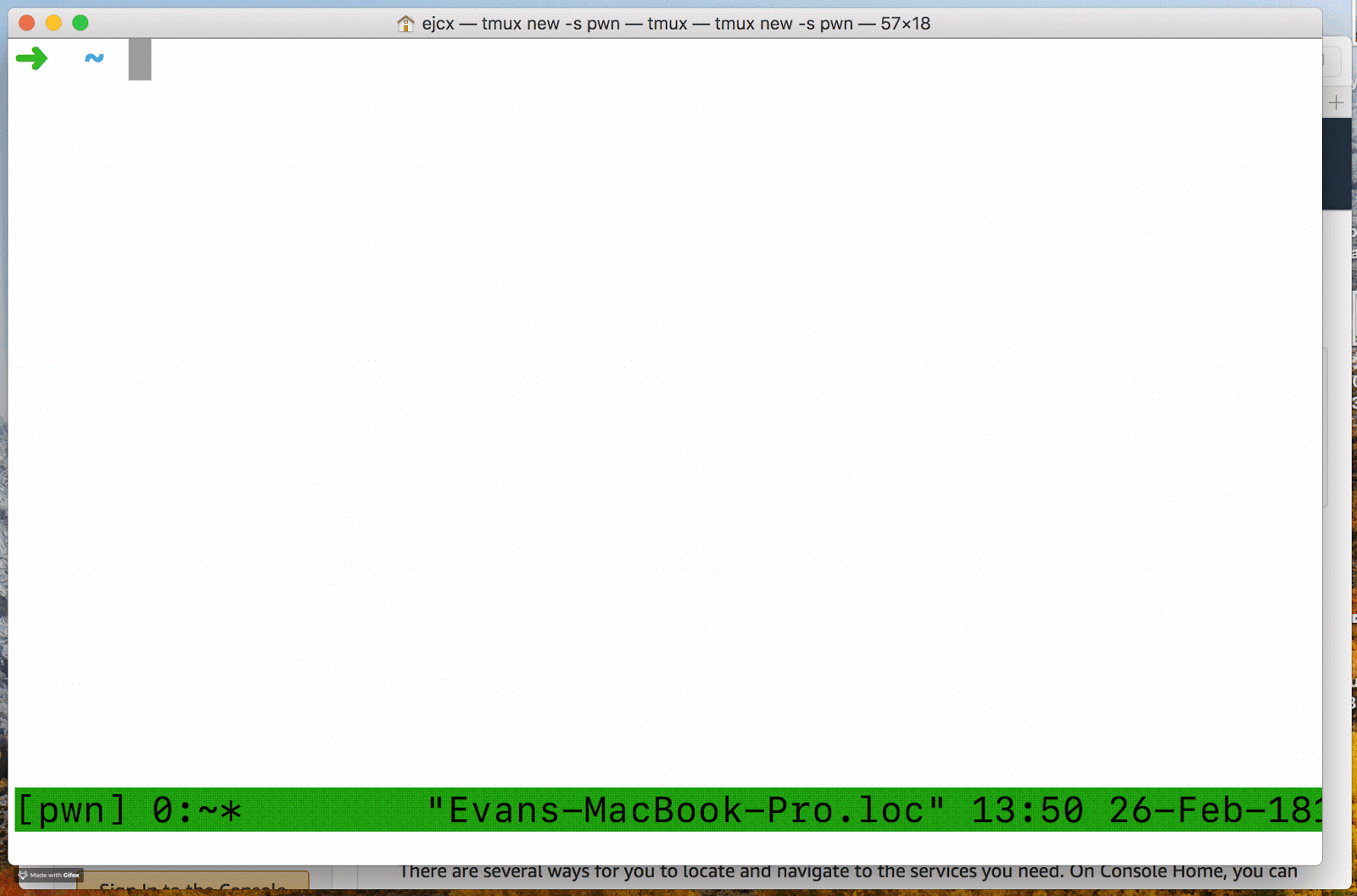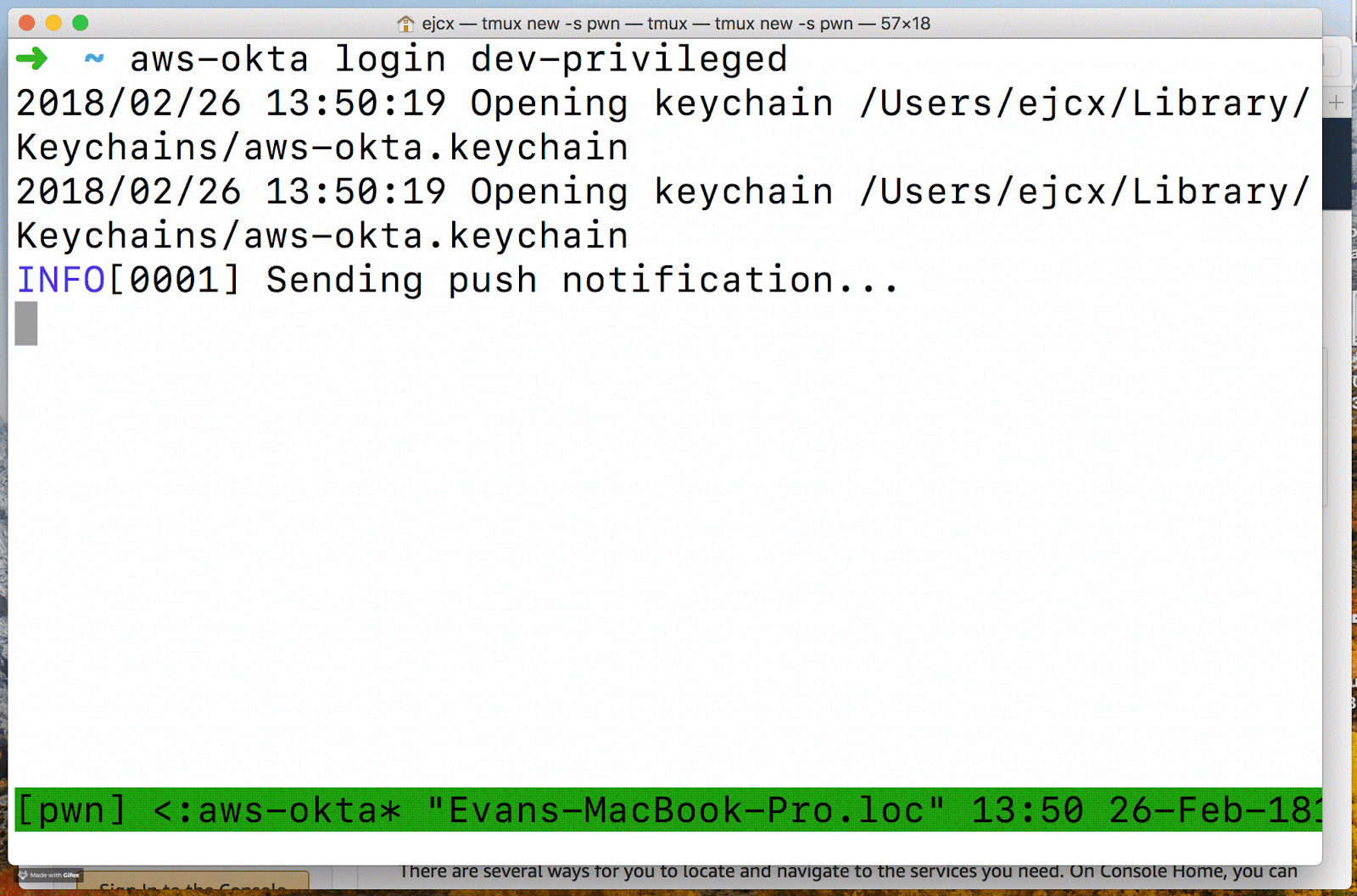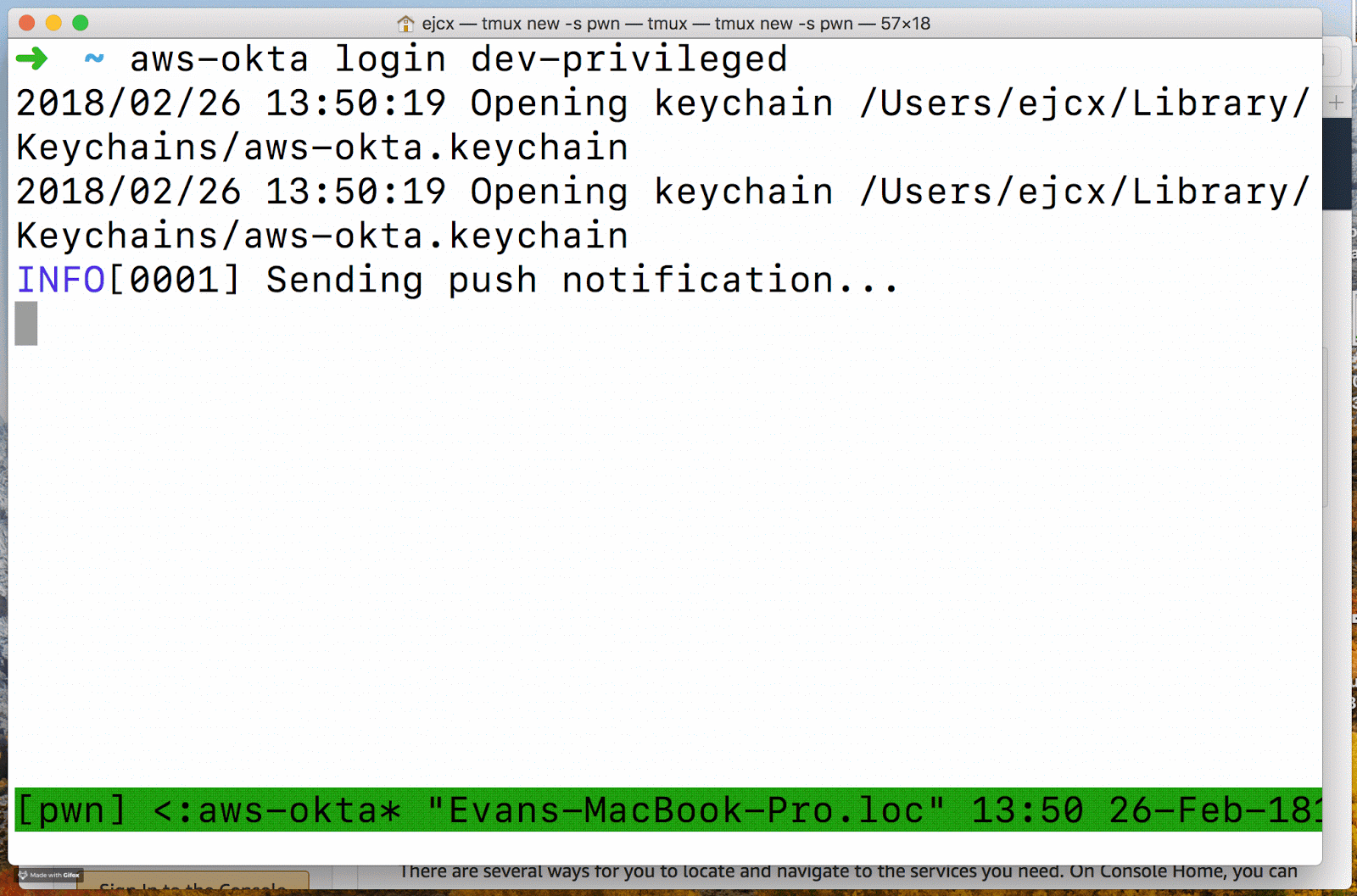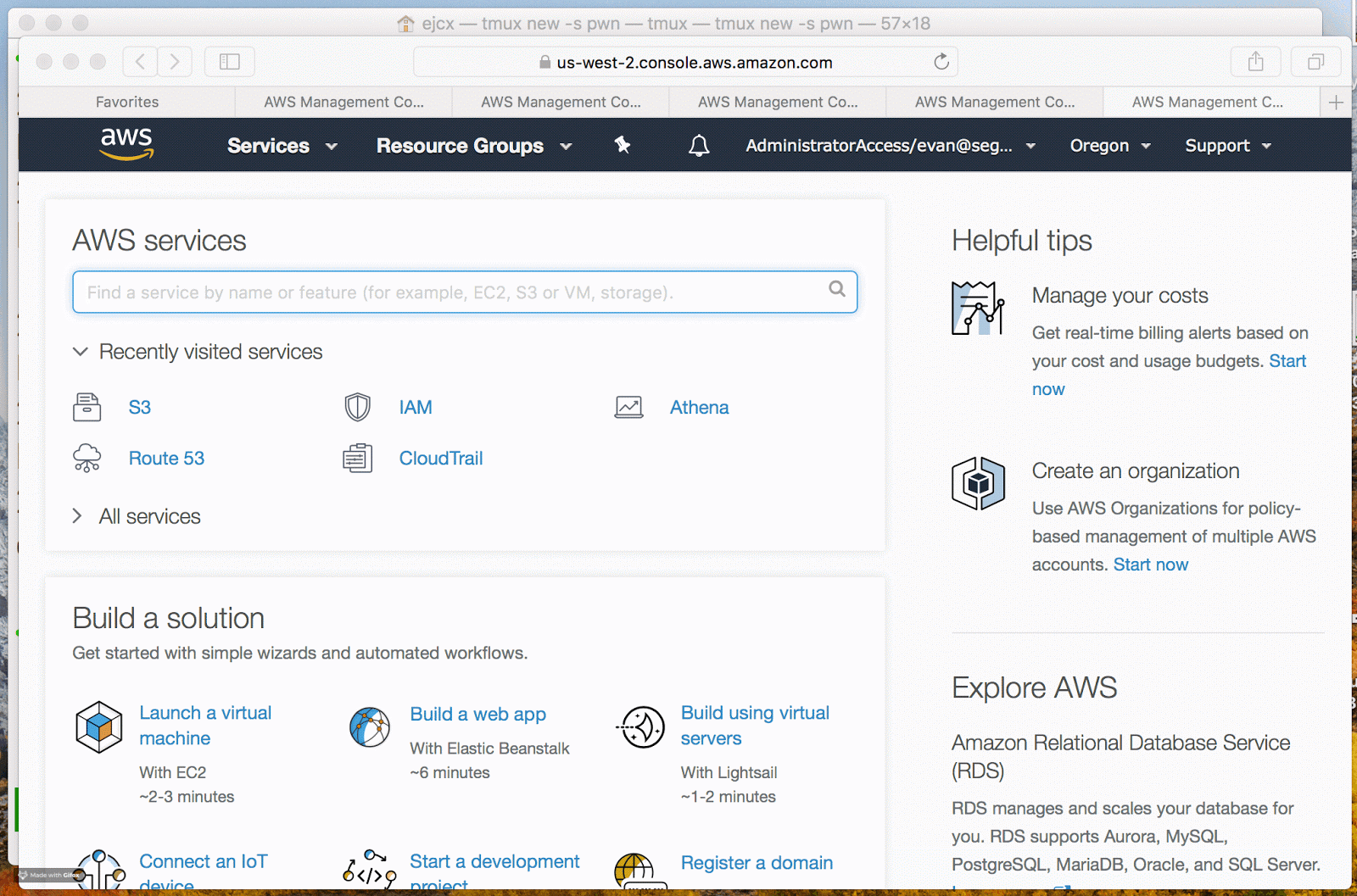
После ответа на уведомление о нажатии Duo aws-okta откроет браузер и войдет в систему указанной роли всего через несколько секунд. Эта функция поддерживается функцией AWS Custom Federated Login, но по ощущениям больше похоже на волшебство при его использовании, что упрощает вход.
За пределами 100 учетных записей
Мы собираемся приблизиться к 50 учетным записям AWS к концу этого года. Безопасность по умолчанию полностью закрыта для учетной записи, и преимущества надежности изолированных лимитов на каждую учетную запись являются непреодолимыми.
Система, которую мы создали, является устойчивой и применимой для масштабирования нашего использования AWS в отношении сотен учетных записей AWS и гораздо большего числа команд инженеров.
Удаление всех ключей AWS сотрудников чрезвычайно удовлетворительно с точки зрения безопасности, и этого достаточно для интегрирования вашего провайдера идентификационных данных с Вашей учетной записью хаба AWS.
Такое или подобное решение, можем реализовать для вашей задачи, обращайтесь office@itfb.com.ua