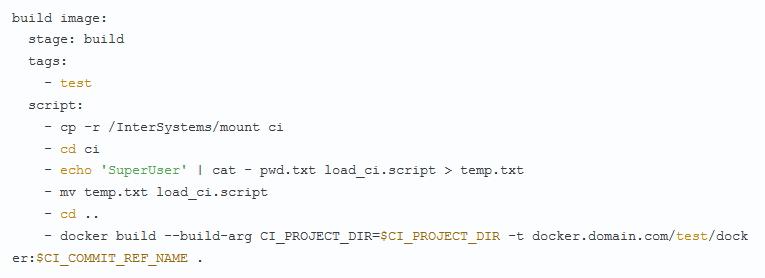
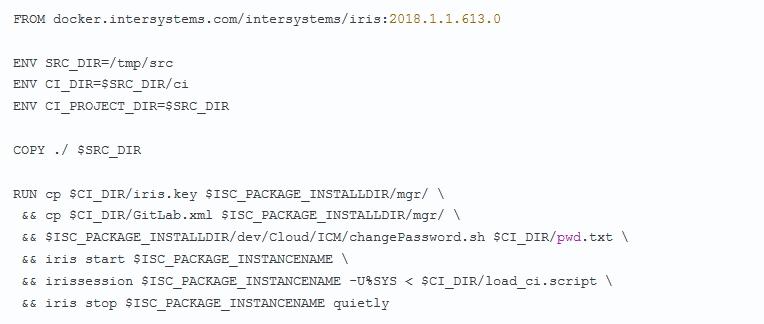
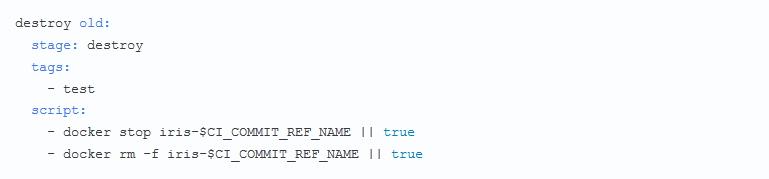
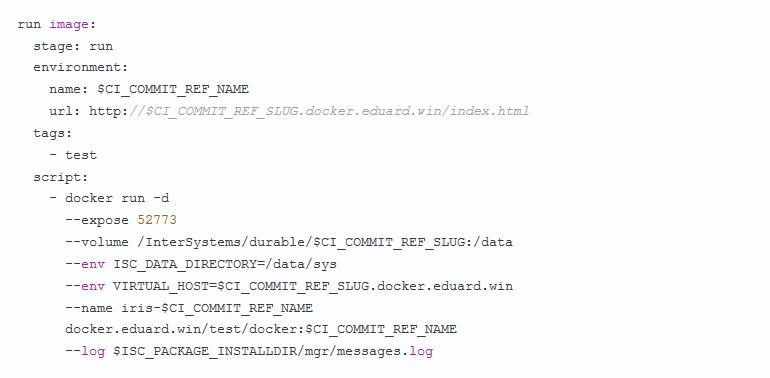
Добрый день уважаемые читатели. Эта статья посвящена теме того как выявлять инструмент атак на Windows инфраструктуру.
В компании Позитив Текнолоджиз мы отвечаем за обнаружение Атак на сетевом уровне. Важной частью нашей повседневной деятельности является проведение Thread Hunting, то есть охота за угрозами в инфраструктуре заказчика.
Для этого мы пишем IDS правила, и на сегодняшний день их уже 4000. Часть из них мы публикуем в нашем открытом твиттере Attack Detection.
План статьи
В начале мы рассмотрим 3 популярных инструмента для проведения атак на Windows инфраструктуру, затем возьмем по 2 модуля из каждого и разберем как они работают, какую сетевую активность создают и как их можно обнаружить. И в качестве завершения статьи мы покажем Mapping техник из данных инструментов на матрицу атак ATT&CK.
Инструменты, о которых мы сегодня будем говорить называются Impacket, CME и Coadic.
Impacket представляет собой набор Python модулей, и является основой разработки инструментов для атак. он поддерживает большое количество протоколов, которые используются в Windows инфраструктуре, и поставляется сразу с 46-ю готовыми модулями. Также комьюнити его активно развивает, о чем свидетельствует более 700 форков на Github.
Следующий инструмент CME – по сути это швейцарский нож. Он автоматизирует многие действия, которые требуется произвести атакующему для продвижения внутрь инфраструктуры, начиная от удаленного перечисления сессий на хостах, до удаленного выполнения команд и запуска mimikatz в памяти с помощью PowerShell.
И, наконец, третий инструмент – Koadic, он самый новый. Был представлен на 25-м Devcon, летом 2017 года. И является продолжателем популярного в последние годы тренда living of the land, что означает использование встроенной в Windows функциональности, только вместо PowerShell он выполняет команды удаленно с помощью Windows Scripting host, который нам известен по интерпретатором JS кода и VB скрипт.
Стоит отметить что все инструменты, которых мы сегодня говорим, используются не для первичного проникновения, а для развития атаки внутри инфраструктуры.
Детальный разбор
Данные инструменты также активно используются APT группировками. Например DragonFly использовала Impacket и CME в октябре 2017 года для атак на энергетическую структуру США.
Группировка Sofacy адаптировала под свои нужды новый инструмент Koadic, и в июне 2018 года провела атаки на правительственные организации Северной Америки и Европы.
Группировка Muddy Water продолжает атаковать военные организации Ирака и Саудовской Аравии.
Impacket
И так, начнем с первого инструмента. Функциональность Impacket весьма широка. Начиная от разведки внутри ActiveDirectory и сбора данных с внутренних MS SQL серверов, продолжая техниками для получения учетных записей. Эти учетные записи можно использовать для удаленного выполнения команд. Impacket умеет это делать через 4 разных транспорта.
Давайте рассмотрим Secretsdump. Целью этого модуля могут быть как машины пользователей, так и контроллеры домена. Его можно увидеть на разных стадиях атаки.
Первым шагом в работе модуля является аутентификация через SMB. для нее необходим либо пароль пользователя в открытом виде, либо его хэш. Далее идет запрос на открытие сервис контроль-менеджера, после которого получение доступа к реестру по протоколу WinReg. Имея WinReg атакующий может узнать данные интересующих его веток и получить результаты через SMB.
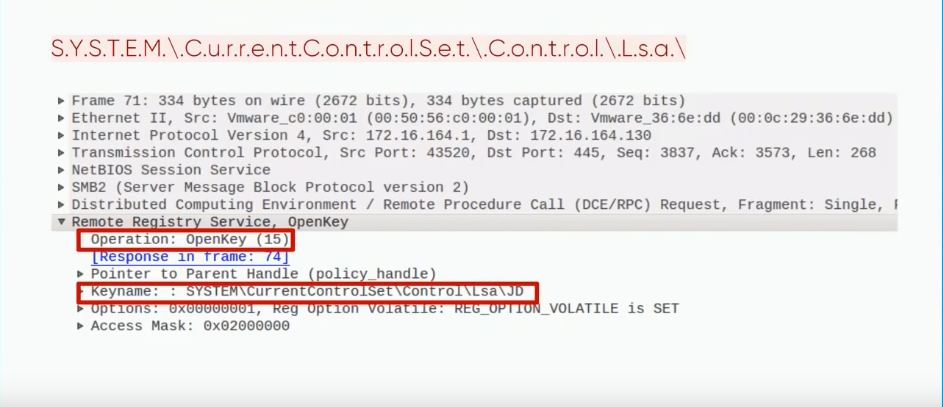
Здесь мы видим запрос в ветку Control/LSA. Аналогичным образов выглядит запрос в ветку НТДС. Для обнаружения нам важно имя ключа.
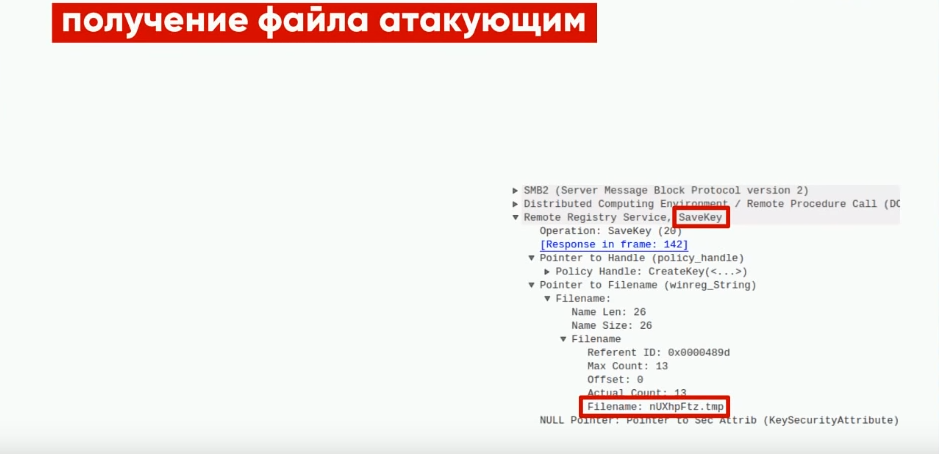
Когда доступ с помощью OpenKey уже получен, скрипт выполняет операцию SaveKey. при сохранении значения по ключу, указывается имя файла, в которое запишутся данные.
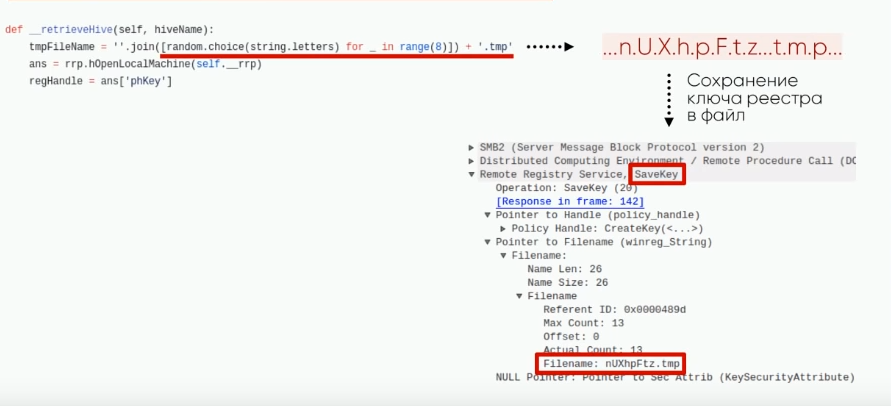
Secretsdump использует достаточно примечательное имя. Исходный код дает ответ на то откуда оно такое. Оно берет в код 8 случайных буквенных символов и добавляет к нему “.tmp”, что мы и видим в трафике. Когда значение получено и выгружено в файл, мы можем видеть процесс загрузки этого файла на машину атакующего. отсюда становится понятно, что для сохранения файла и последующей загрузки атакующий использует system32 шару.
Как и многие другие инструменты для пост эксплуатации, Impacket имеет модули для удаленного выполнения команд. Мы остановимся на smbexec И он будет вторым модулем который мы рассмотрим.
Он дает атакующему интерактивную командную оболочку. Для этого модуля также требуется аутентификация через SMB, как и для первого, рассмотренного нами. Далее открывается сервис контроль менеджер, создается и стартует сервис. После этого злоумышленник получает командную оболочку.
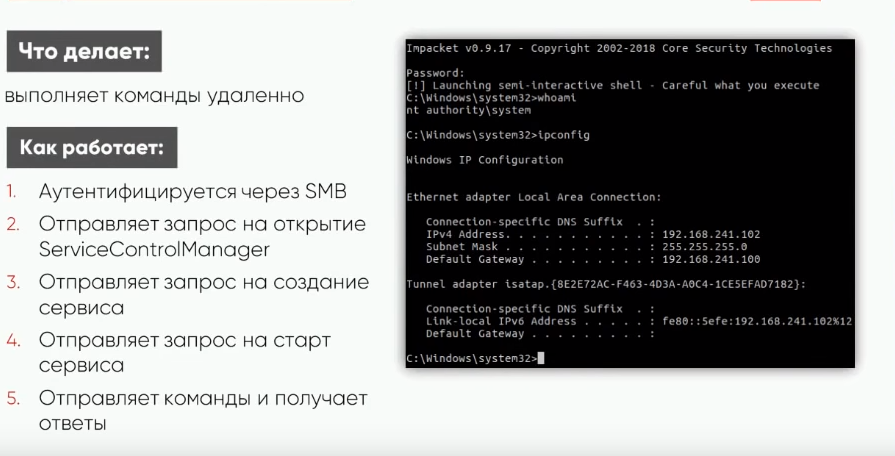
На картинке мы можем видеть пример исполнения такого скрипта. В данном случае атакующий получает консоль локального администратора.
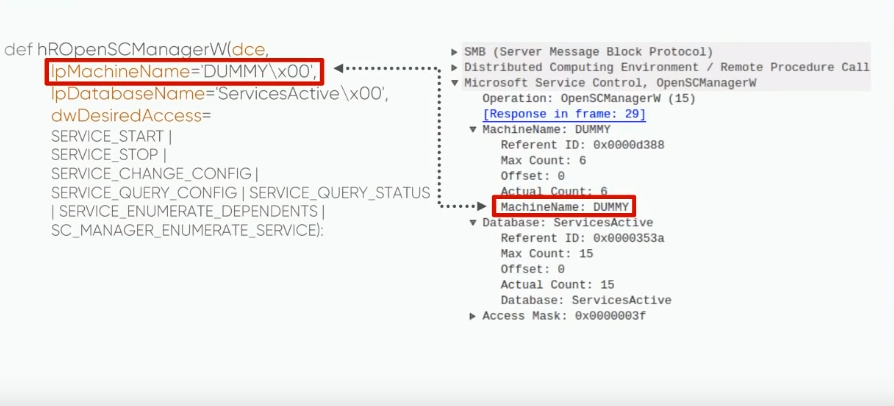
Так выглядит запрос на открытие сервиса контроль-менеджера. Примечательно в нем то, что поле machine name имеет значение dummy. Ответ на это мы нашли в исходном коде и убедились в том что это хард код.

После открытия SCM происходит создание сервиса. В случае с smbexec Мы можем видеть каждый раз одинаковую логику построения команды. То есть в начале идет командный интерпретатор, а после идет имя файла, в который выводится результат выполнения команды. Потом идет файл с названием команды и в конце удаление этого файла.
Зеленым цветом здесь отмечены неизменные параметры, желтым, то что атакующий может изменить.
Impacket является мощным инструментом, но как и все программы он призван автоматизировать, поэтому он имеет свои характерные особенности, которые мы с вами сейчас увидели на примере работы пары модулей. Здесь конкретные winreg запросы, использование SCM API с характерным формированием команд, и формат имен файлов и SMB шара system32.
Мы реализовали подобную экспертизу на наш продукт. PTN Work attack discovery. Он предназначен для выявления атак в сетевом трафике, расследования инцидентов. Вот как детекты выглядят на практике.

Здесь мы видим результат анализа модуля secretsdump. Здесь происходит открытие SCM. Мы видим запросы в ветку LSA CMS Security и НТДС. Также мы можем видеть анализ дампа трафика с smbexec.
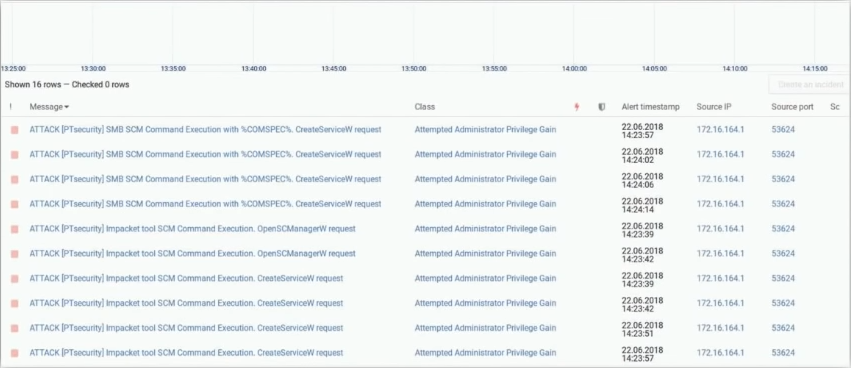
Здесь мы видим обращение к SCM.
CrackMapExec
Вторым инструментом, который мы сегодня рассмотрим является CrackMapExec. В будущем мы будем называть его просто CME.
Чем опасен Empire
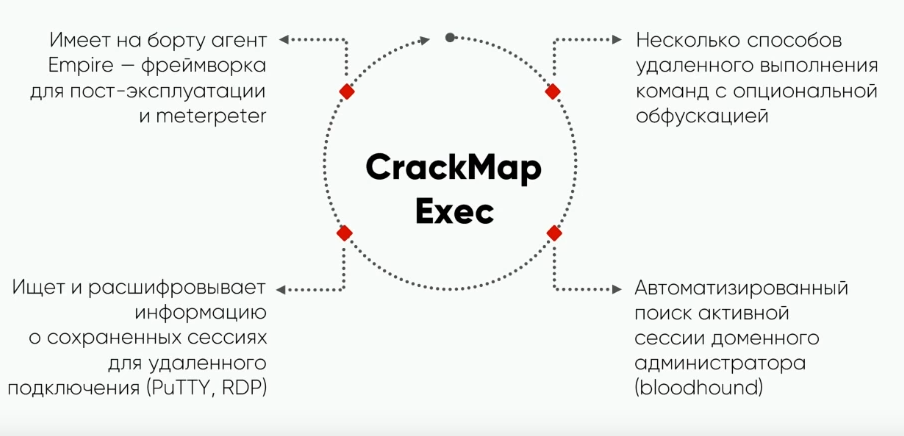
СМЕ призван в первую очередь автоматизировать все рутинные действия, которые приходится выполнять атакующему для продвижения внутри сети. Надо закинуть интерактивный шилл на хост. Для этого он имеет интеграцию с небезызвестными Empire и Meterpeter. Чтобы скрытно выполнять команды, СМЕ умеет их обфусцировать.
Чтобы автоматизировать поиск активной сессии доменного администратора, он использует инструмент Bloodhound. Он собирает информацию о пользователях, группах и машинах, а также проводит сессии активных залогиненных пользователей внутри Active Directory.
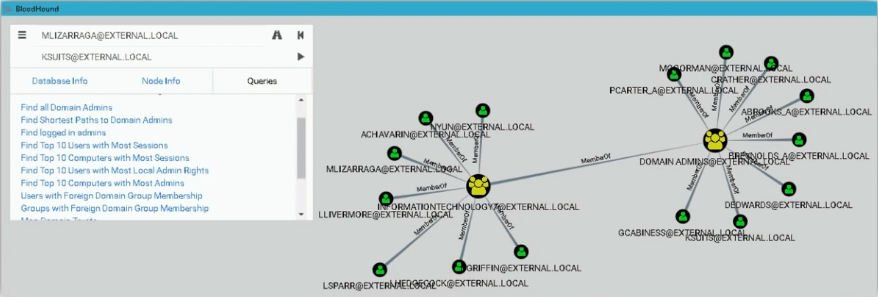
Так выглядит его интерфейс. В левой части скриншота вы можете видеть сразу встроены по дефолту запросы, одним из которых является найти самый кратчайший путь до машины, где залогинен доменный администратор.
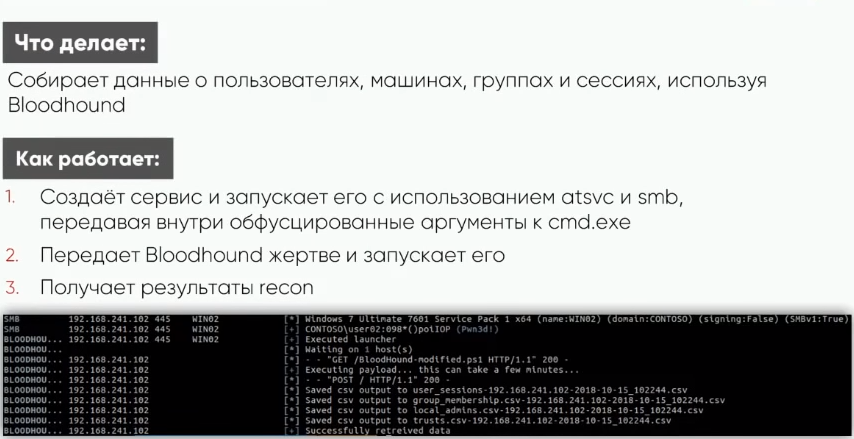
Так в чем же проблема, и зачем СМЕ, если есть бладхаунд? Дело в том что скрипт или бинарный файл должен попасть как-то на машину жертвы. Желательно максимально незаметно. После чего отдать данные и исполниться.
СМЕ модель как раз решает эту проблему. Он создает сервис с использованием atsvc и smb. Далее жертва получает бладхаунд скрипт и исполняет его. После сбора данные отправляются на машину атакующего.

Atsvc – это сервис удаленного планировщика задач виндовс. В нем есть функция создания задач. На вход сервису должна поступить xml-ка, в которой будет сказано, что нужно выполнить. На картинке мы видим вырезку из подобно xml-ки, которая было отправлена CME. В правой части картинки мы видим поле команд.
В нем содержится cmbexec, а также в качестве аргументов указан powershell с явной дальнейшей обфускацией. Таким образом на машине жертвы появляется и запускается бладхаунд.

Первым делом после запуска бладхаунд запрашивает список пользователей домена и список машин домена. На левой стороне картинки запрос с фильтром для получения пользователя. Он выделен красным. А на правом для машины.

Когда основные данные получены, скрипт запросит первичные группы в домене и членство пользователей в них. Слева мы можем увидеть сам фильтр в запросе, а справа ответ контроллера домена составам групп.

Бладхаунд выполнил запрос, а привилегированных SID 500/512/519, то есть администратора и административных группах. Он запросит какие активные сессии есть за этими учетными записями. Это требуется для того чтобы выбрать приоритетные машины для проведения дальнейшей атаки на них.

Вторым инструментом СМЕ, на который мы посмотрим является скрипт, который служит для того, чтобы атакующий узнал какие есть антивирусные решения на машине его жертвы. Для того чтобы сделать запрос, он создает инстанс, который передает тело запроса. На скрине показан результат выполнения такого скрипта.

Атакующему необходимо подключиться к namespace виндовс root\SecurityCenter2 чтобы сделать необходимые запросы. Далее происходит запрос классов антиспайвеар продукт и антивирус продукт. По умолчанию у виндовс за эти функции отвечает виндовс дефендер, что подтверждает ответ клиента. Сам запрос выглядит всегда одинаково, и такую активность достаточно легко обнаруживать.

Мы с вами посмотрели на 2 модуля CME. У каждого из них есть свои артефакты. В них входит и специфичные запросы и создание определенного вида задач atsvc с применением обфускации. Характерные для бладхаунд запросы, которые отличные от обычных запросов в виндовс сетях. Также мы увидели не типичную активность через СМБ.
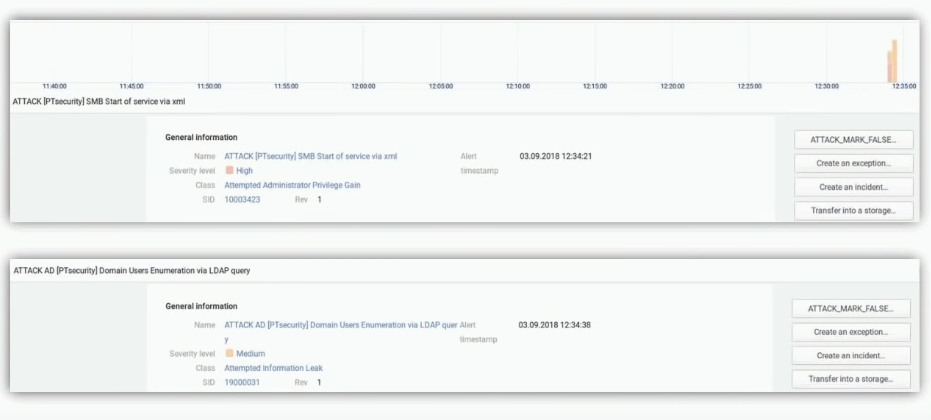
СМЕ не стал исключением и мы научили PTN Work attack discovery обнаруживать его активность.
Мы можем обеспечить должную безопасность сервера путем проведения аудита и закрытия слабых мест вашей инфраструктуры. Обращайтесь к профессионалам!