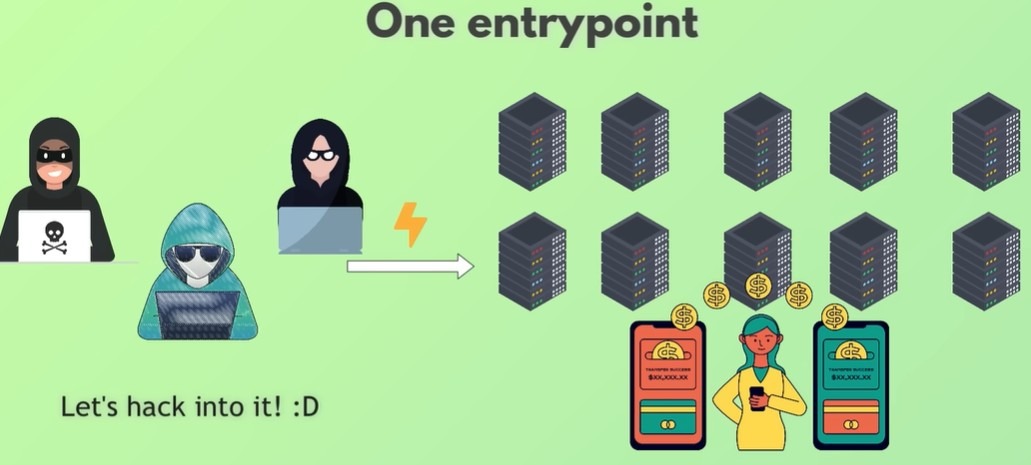
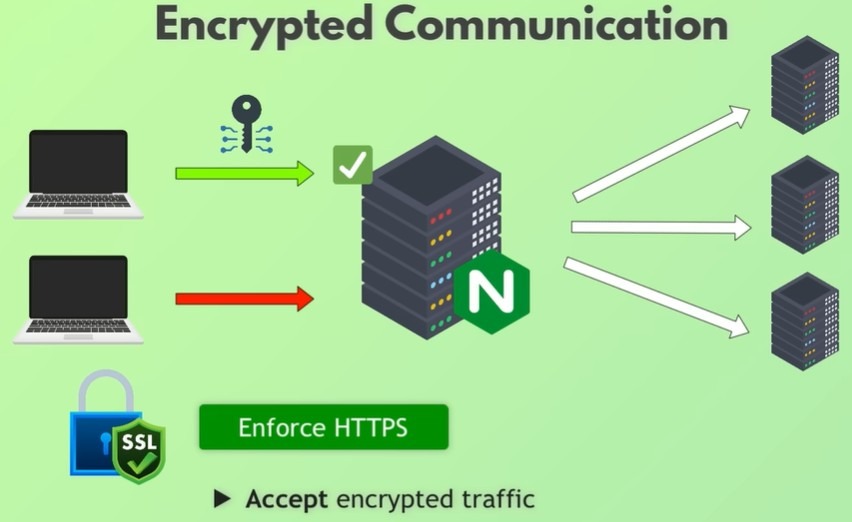
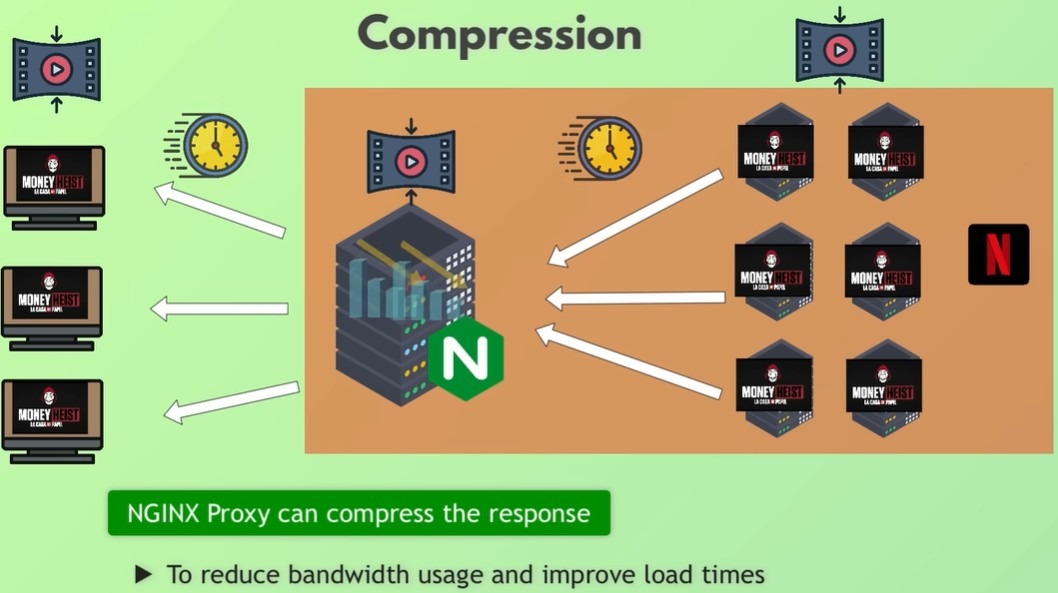
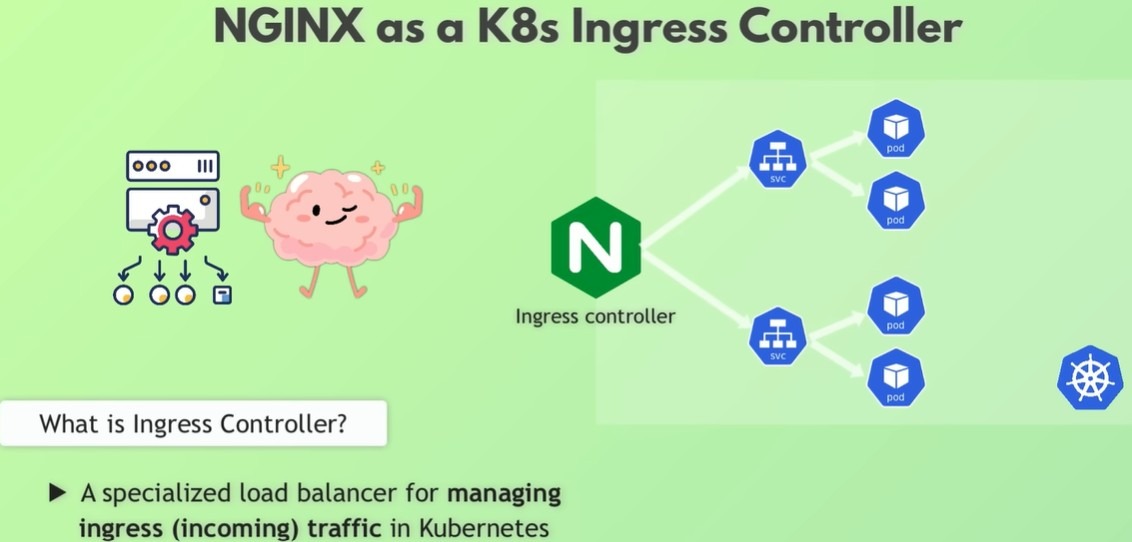
Сетевые технологии — это фундаментальный навык для любого инженера-программиста. Чтобы действительно понять, зачем существуют сетевые концепции и какие реальные задачи они решают, полезно рассматривать их в действии, а не по отдельности.
В этой статье мы проследим развитие вымышленной платформы бронирования путешествий TravelBody. По мере того как приложение эволюционирует от одного сервера до сложной облачной системы, мы будем разбирать каждую сетевую концепцию именно в тот момент, когда она становится необходимой.
От одного сервера к интернету
Когда TravelBody только запускался, всё приложение работало на одном сервере. Такая схема была простой, но сразу возник важный вопрос: как пользователи находят сервер в интернете?
IP-адреса: идентификация устройств в сети
Каждому устройству, подключённому к сети, нужен уникальный идентификатор, чтобы другие устройства знали, куда отправлять данные. Этот идентификатор называется IP-адресом. Он работает так же, как почтовый адрес дома: без него доставка невозможна.
Сервер TravelBody получил публичный IP-адрес, благодаря чему любое устройство в интернете может отправлять запросы напрямую на этот сервер.
DNS: удобные имена для людей
Запоминать IP-адреса неудобно, поэтому используется DNS (Domain Name System). DNS переводит легко запоминаемые доменные имена в IP-адреса.
Когда пользователь вводит travelbody.com в браузере, DNS автоматически находит соответствующий IP-адрес и подключает пользователя к нужному серверу. Это похоже на выбор контакта по имени в телефоне вместо набора полного номера.
Несколько приложений на одном сервере
По мере роста TravelBody на одном сервере начали работать сразу несколько компонентов:
-
пользовательский веб-сайт
-
база данных с информацией о бронированиях
-
сервис обработки платежей
Все они использовали один и тот же IP-адрес, что создало новую проблему.
Порты: направление трафика нужному приложению
Эту задачу решают порты. Порты — это пронумерованные каналы связи на сервере, от 1 до 65 535. Каждое приложение «слушает» свой порт.
Например:
-
веб-приложение: порт 80 (HTTP) или 443 (HTTPS)
-
база данных MySQL: порт 3306
-
платёжный сервис: порт 9090
Когда запрос приходит на сервер, номер порта указывает операционной системе, какому приложению его передать. IP-адрес — это адрес здания, а порты — номера квартир внутри него.
Повышение безопасности с помощью сегментации сети
Хранение платёжных данных и персональной информации на одном сервере создавало серьёзные риски безопасности. В случае взлома злоумышленник получал бы доступ ко всему сразу.
Подсети: разделение сети
Для снижения рисков была внедрена сетевая сегментация с использованием подсетей. Подсети разделяют сеть на изолированные зоны с разным назначением:
-
публичная подсеть для фронтенд-серверов
-
приватная подсеть для серверов приложений
-
отдельная подсеть для баз данных
Такое разделение ограничивает доступ и уменьшает последствия возможной атаки.
Маршрутизация: связь между сегментами
Когда появляются подсети, возникает необходимость их соединять. Маршрутизация определяет, как данные перемещаются между сегментами сети — аналогично GPS, который прокладывает маршрут из точки А в точку Б.
Контроль трафика с помощью межсетевых экранов
То, что сети могут обмениваться данными, не означает, что им следует это делать без ограничений. Здесь на сцену выходят межсетевые экраны (firewalls).
Firewalls: применение правил безопасности
Межсетевой экран проверяет сетевой трафик и разрешает или блокирует его на основе заданных правил.
Существуют два основных типа:
-
host-firewalls, защищающие отдельные серверы
-
network-firewalls, фильтрующие трафик между подсетями
Например:
-
сервер базы данных принимает подключения только на порт 3306 и только из подсети приложений
-
фронтенд-подсеть принимает входящий интернет-трафик только на портах 80 и 443
Многоуровневая защита означает, что злоумышленнику нужно пройти несколько уровней безопасности, чтобы нанести вред.
Приватные сети и доступ в интернет
С ростом TravelBody появились десятки бэкенд-серверов, работающих в приватных подсетях. Эти серверы используют приватные IP-адреса, недоступные напрямую из интернета.
NAT: безопасный выход в интернет
При этом приватным серверам всё равно нужен доступ в интернет, например для:
-
загрузки обновлений
-
обращения к внешним API
Эту задачу решает NAT (Network Address Translation). NAT позволяет нескольким серверам с приватными IP-адресами использовать один публичный IP для исходящих соединений.
Процесс выглядит так:
-
сервер отправляет запрос на NAT-устройство
-
NAT подменяет приватный IP своим публичным
-
ответ из интернета возвращается обратно нужному серверу
Так серверы остаются скрытыми, но сохраняют доступ к внешним ресурсам.
Переход в облако
Управление физическими серверами стало дорогим и медленным, поэтому TravelBody перешёл в облако, арендуя вычислительные ресурсы вместо владения оборудованием.
Сетевые принципы остаются теми же
Хотя инфраструктура изменилась, сетевые основы остались прежними:
-
IP-адреса
-
порты
-
подсети
-
маршрутизация
-
firewalls
-
NAT
В облаке эти элементы предоставляются как управляемые сервисы.
Virtual Private Cloud (VPC)
VPC — это изолированная часть сети облачного провайдера. Это похоже на аренду собственного этажа в большом офисном здании. Внутри VPC TravelBody воссоздал привычную архитектуру с публичными и приватными подсетями, таблицами маршрутизации, интернет-шлюзами и NAT-шлюзами.
Контейнеры и переносимость приложений
При переходе к микросервисной архитектуре сложность развертывания резко выросла. Различия между средами разработки и продакшена начали вызывать ошибки.
Контейнеры: упаковка приложений
Контейнеры упаковывают всё необходимое для работы приложения — код, среду выполнения, библиотеки и настройки — в один переносимый объект. Это гарантирует одинаковое поведение приложения в разных средах.
Для контейнеризации сервисов TravelBody использовался Docker.
Сетевое взаимодействие контейнеров
Контейнеры взаимодействуют через:
-
bridge-сети для связи на одном сервере
-
проброс портов, позволяющий получать доступ к контейнерам извне
-
overlay-сети, объединяющие контейнеры на разных серверах в одну виртуальную сеть
Эти механизмы по сути повторяют знакомые сетевые концепции, такие как NAT и маршрутизация.
Kubernetes: управление контейнерами в масштабе
Когда TravelBody начал запускать сотни контейнеров на десятках серверов, ручное управление стало невозможным.
Поды и IP-адреса
В Kubernetes контейнеры запускаются внутри подов. Каждый под получает собственный IP-адрес, общий для всех контейнеров внутри него.
Однако поды являются временными: они могут удаляться, пересоздаваться и перемещаться, при этом их IP-адреса меняются.
Сервисы: стабильная сеть для динамических подов
Эту проблему решают Kubernetes-сервисы. Сервис предоставляет:
-
постоянный IP-адрес
-
стабильное DNS-имя
Сервис автоматически направляет трафик к здоровым подам, даже если они пересоздаются. Приложения подключаются к сервису, а не к конкретному поду.
Публикация приложений с помощью Ingress
Чтобы сделать сервисы доступными из интернета, в Kubernetes используется Ingress.
Ingress выступает в роли единой точки входа, распределяя входящие запросы между сервисами на основе доменов или путей URL.
Например:
-
запросы к
travelbody.comнаправляются в веб-сервис -
API-запросы — в сервисы бронирования или платежей
Ключевые сетевые основы: итог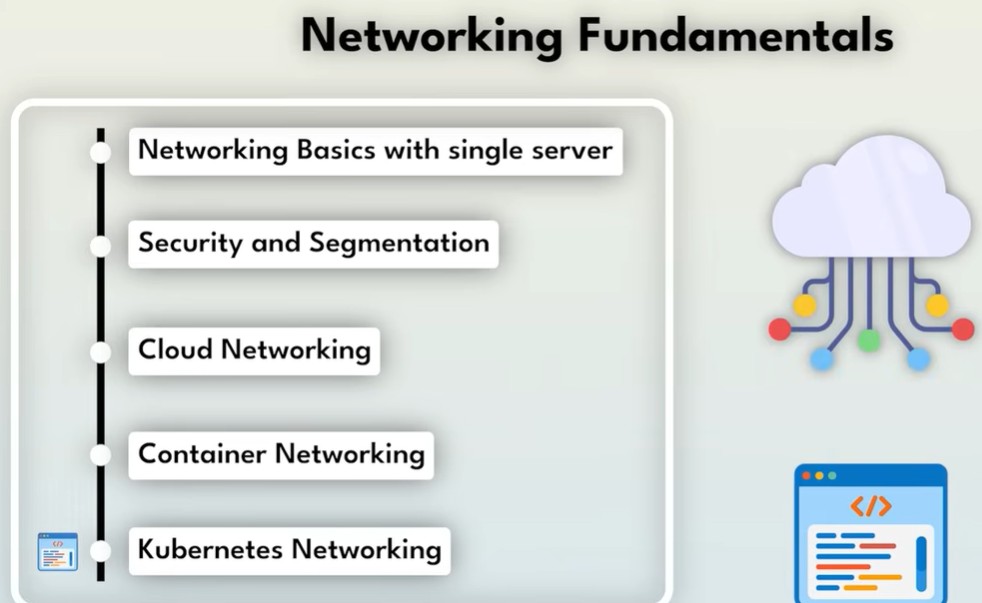
Мы выделили пять фундаментальных сетевых концепций:
-
IP-адреса и DNS — идентификация устройств и преобразование имён
-
Порты — направление трафика нужному приложению
-
Подсети и маршрутизация — организация сети и связь сегментов
-
Firewalls — контроль и защита сетевого трафика
-
NAT — безопасный доступ приватных систем в интернет
Эти принципы работают везде: на физических серверах, в облаке, в контейнерах и в Kubernetes. Инструменты меняются, но основы остаются неизменными.
Освоив эти фундаментальные концепции, инженер сможет понимать, проектировать и эффективно устранять проблемы в системах любого масштаба.