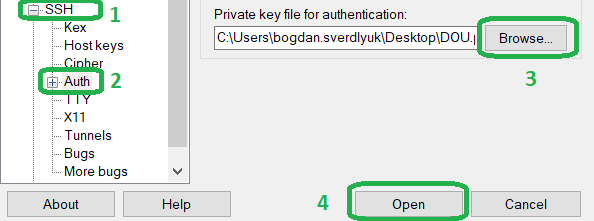
Общий обзор реляционных баз данных Azure и AWS
Ниже есть общая таблица, основываясь на ней, мы видим, какие СУБД представлены в облаке как сервисе (SaaS).
 Представление реляционных баз данных в облаках
Представление реляционных баз данных в облаках
СУБД в AWS представлены в рамках единого сервиса RDS
На самом деле, при создании экземпляра базы данных в RDS (relational data service) вы будете встречать особенности конкретных СУБД, а не общего сервиса RDS.
То есть, если вы разворачиваете MS SQL Server, вам необходимо выбрать тип лицензирования — Enterprise, Standard, Express или Web edition, выбрать версию (2012-2019), диски и мощности виртуальной машины, на которой будет развернут экземпляр, и сконфигурировать инфраструктуру. Если работа будет с другими видами СУБД, то соответственно все конфигурируется под конкретную СУБД со всеми ее особенностями.
Таким образом, RDS в большинстве своем повторяет и реализует полноценные СУБД, и при выборе и настройке пользователи руководствуются знаниями о наземных полноценных реализации.
Это позволяет сохранять полную совместимость с наземными экземплярами, что облегчает миграцию при определенных сценариях и предоставляет доступ на уровне операционной системы.
СУБД в Azure выделены в отдельные сервисы
Сервисы в Azure преимущественно позволяют сконцентрироваться на разработке приложений и решений с нуля, могут использоваться под различные типы нагрузок с возможностью изменять технические характеристики в зависимости от интенсивности нагрузок, типа или условий. Такие изменения технических характеристик могут происходить по требованию автоматически или по регламенту, и эти возможности описывают уровень масштабируемости сервисов.
Способность к масштабируемости обусловлена тем, что управление инфраструктурой в большинстве сервисов СУБД полностью выносится на уровень ответственности Microsoft, а на уровне пользователя остается только управление данными и приложением.
RDS также относится к PaaS, но, поскольку обеспечивает полную совместимость с наземными экземплярами, требует более глубокого понимания специалиста именно особенностей наземных полноценных инстанций.
Облачные сервисы СУБД в Azure имеют свои подходы, поддерживают полную совместимость кода, но не обеспечивают полной совместимости с полноценной версией СУБД, проекцией которой они являются.
Это обусловлено и тем, что Microsoft пытаются реализовать более высокую гранулярность функционала. Если говорить обобщенно, они выделяют функционал в отдельные услуги или настройки, тарифицируемые отдельно. Это позволяет построить прозрачный и гибкий подход к ценообразованию, что в случае правильно выбранного сервиса и настроек позволит построить оптимальное решение с точки зрения цена/производительность.
Условно говоря, функционал MS SQL Server в облаке может быть разделен на отдельные услуги, обладающие собственными принципами ценообразования.
Для многих сценариев «полный комплект» действительно избыточен, и зачастую достаточно будет только использование функционала базы данных, а не всех сопутствующих сервисов сразу, за доступность которых клиент так или иначе платит платежи, покрываемые лицензией полноценного инстанса.
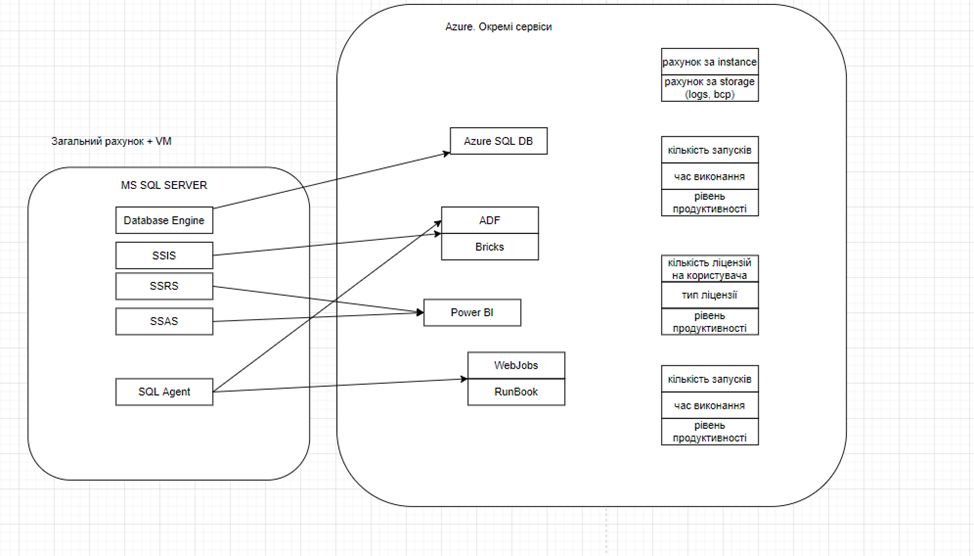 Пример: Гранулярность – неисчерпаемое количество возможных сервисов и факторов ценообразования.
Пример: Гранулярность – неисчерпаемое количество возможных сервисов и факторов ценообразования.
Кроме того, Azure имеет более широкую линейку предложений вариантов баз данных, относящихся к типам СУБД MS SQL server. На самом деле это неудивительно, поскольку Azure – это Microsoft, и SQL server – это тоже Microsoft.
Компания пытается расширять свою линейку предложений, чтобы удовлетворить разных пользователей с разными рабочими задачами — от полных новичков, которые хотят попробовать поработать с базами данных и понять, как это — установить БД без лишних хлопот, до опытных разработчиков или администраторов избирающих баз данных. и достаточно тонко конфигурируют БД под промышленные нагрузки.
При этом все равно многие административные вопросы будут оставаться на стороне Microsoft.
Многое то, что умеет делать RDS с базами данных SQL server, будет уметь и Azure, но дополнительно он будет предлагать еще больше гибридных версий под разных пользователей и под разные кейсы.
Предлагаю подробнее рассмотреть предложения Azure и AWS.
Что предлагает Microsoft в рамках Azure SQL
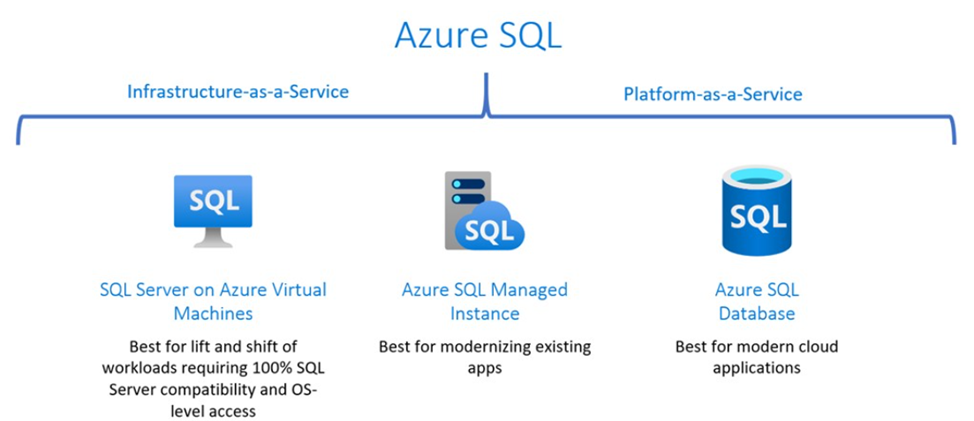 Модели развертывания в Azure SQL
Модели развертывания в Azure SQL
Что предлагает AWS
Реляционная база данных – это виртуальная машина с установленным MS SQL Server. SQL Server on Azure Virtual Machines – это тождественные сервисы (IaaS).
Далее AWS предлагает упоминаемый RDS из MS SQL Server (SaaS).

Здесь вы не будете управлять виртуальной машиной, но будете ее выбирать из многих типов. Необходимо разбираться не только в простых и главных показателях эффективности базы данных, а именно IOPS, memory, CPU – нужно будет понимать характеристики виртуальных машин. Да, конечно, существует документация, но эта история будет более сложной для чистых разработчиков или аналитиков, а не профильных админов.
Опять же, Azure также дает возможность тонко подходить к вопросу.
Azure имеет managed instance, тип Azure SQL, наиболее соответствующий RDS, где также выбирается виртуальная машина. Нужно понимать ее особенности и конфигурационные детали, но дополнительно Azure SQL single database, действительно работающая как услуга, наиболее очищена от инфраструктурных вопросов и является «чистым» database engine.
|
Azure |
AWS |
| Виртуальные машины (IaaS) |
MS SQL Server on VM |
MS SQL Server on EC2 |
| Услуги (SaaS) (Hybrid) |
Managed Instance |
MS SQL Server на RDS |
| Услуги (SaaS) |
Azure SQL Single Database |
|
При этом обеспечивается стандарт T-SQL для всех версий.
Например, варианты выбора параметров виртуальной машины (ec2) для RDS.
| Name |
Instance Type |
Memory |
Storage |
Processor |
vCPUs |
Network Performance |
Arch |
| M1 General Purpose Medium |
db.m1.medium |
3.75 GiB |
1×410 |
intel Xeon Family |
1 vCPUs |
Moderate |
64-bit |
| M1 General Purpose Small |
db.m1.small |
1.7 GiB |
1×160 |
intel Xeon Family |
1 vCPUs |
Low |
64-bit |
| M3 General Purpose Medium |
db.m3.medium |
3.75 GiB |
1×4 SSD |
Intel Xeon E5-2670 v2 (Ivy Bridge/Sandy Bridge) |
1 vCPUs |
Moderate |
64-bit |
| T1 Micro |
db.t1.micro |
0.613 GiB |
0 GiB (EBS only) |
Variable |
1 vCPUs |
Very Low |
64-bit |
| T2 General Purpose Micro |
db.t2.micro |
1 GiB |
0 GiB (EBS only) |
Intel Xeon Family |
1 vCPUs |
Low to Moderate |
64-bit |
| T2 General Purpose Small |
db.t2.small |
2 GiB |
0 GiB (EBS only) |
Intel Xeon Family |
1 vCPUs |
Low to Moderate |
64-bit |
| M1 General Purpose Large |
db.m1.large |
7.5 GiB |
2×420 |
Intel Xeon Family |
2 vCPUs |
Moderate |
64-bit |
| M2 High Memory Extra Large |
db.m2.xlarge |
17.1 GiB |
1×420 |
Intel Xeon Family |
2 vCPUs |
Moderate |
64-bit |
Часть параметров, которые конфигурируются: Allocated storage, Architecture settings, Auto minor version upgrade, Availability zone, AWS KMS key, Backup replication, Backup retention period, Backup target, Backup window, Character set, Collation, Copy tags to sna Database management type, Database port, DB engine version, DB instance class, DB instance identifier, DB parameter group, DB subnet group, Deletion protection, Encryption, Enhanced Monitoring, Engine type, Initial database name, License, Log exports, Mainten Master password, Master username, Microsoft SQL Server Windows Authentication, Multi-AZ deployment, National Character Set (NCHAR), Network type, Option group, Performance Insights, Provisioned IOPS, Public access, Storage autoscaling, Storage type, Time zone, Virtual Private Cloud (VPC),VPC Security Group (Firewall).
Для некоторых параметров есть свои вложенные параметры.
В противоположность варианты для создания Azure SQL
Azure SQL имеет две общие модели развертывания, классифицируемые более компактно (их подробно опишу в следующих статьях об облачных базах).
Первая модель
|
Basic |
Standard |
Premium |
| Target workload |
Разработка и производство |
Разработка и производство |
Разработка и производство |
| Uptime SLA |
99.99% |
99.99% |
99.99% |
| Maximum backup retention |
7 дней |
35 дней |
35 дней |
| CPU |
Low |
Low, Medium, High |
Medium, High |
| IO throughput (approximate) |
1-5 IOPS per DTU |
1-5 IOPS per DTU |
25 IOPS per DTU |
| IO latency (approximate) |
5 ms (read), 10 ms (write) |
5 ms (read), 10 ms (write) |
2 ms (read/write) |
| Columnstore indexing |
N/A |
S3 и выше |
Supported |
| In-memory OLTP |
N/A |
N/A |
Supported |
| Maximum DTU |
5 |
3000 (S12) |
4000 (P15) |
| Maximum Storage Size |
2 GB |
250 GB |
1 TB |
Вторая модель:
|
General Purpose |
Business Critical |
| Compute |
1 to 16 vCore |
1 to 80 vCore |
| Storage |
Premium Remote storage, max 4 TB |
Premium Remote storage, max 4 TB |
| IO throughput |
500 IOPS на VCore |
5000 IOPS для DTU VCore |
| Backups |
RA-GRS, 7 – 35 дней |
RA-GRS, 7 – 35 дней |
То есть выбор сервиса унифицирован к типам нагрузки с постепенным масштабированием.
Если Vcore – 1, 2, 4, 8, 16, 32 и так далее. Если DTU – 20, 50, 100, 200, 500, 1000 и так далее.
Конечно, существует множество деталей в выборе типа Azure SQL, большая часть которых имеет бизнес-контекст. Четкое понимание бизнес-потребностей очень важно, ведь технические детали интегрированы в бизнес-определение для облегчения понимания того, какую БД вам необходимо выбрать, если вы не администратор БД, а разработчик или владелец стартапа.
Это тема отдельной статьи, но интересно обратить внимание на ценообразование и стоимость Azure SQL по сравнению с аналогами по производительности других облачных провайдеров. Разница в цене на средних и дорогостоящих планах может превышать 100%, но надо понимать, как балансировать функциональность.
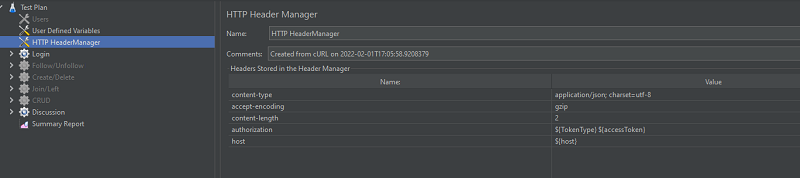
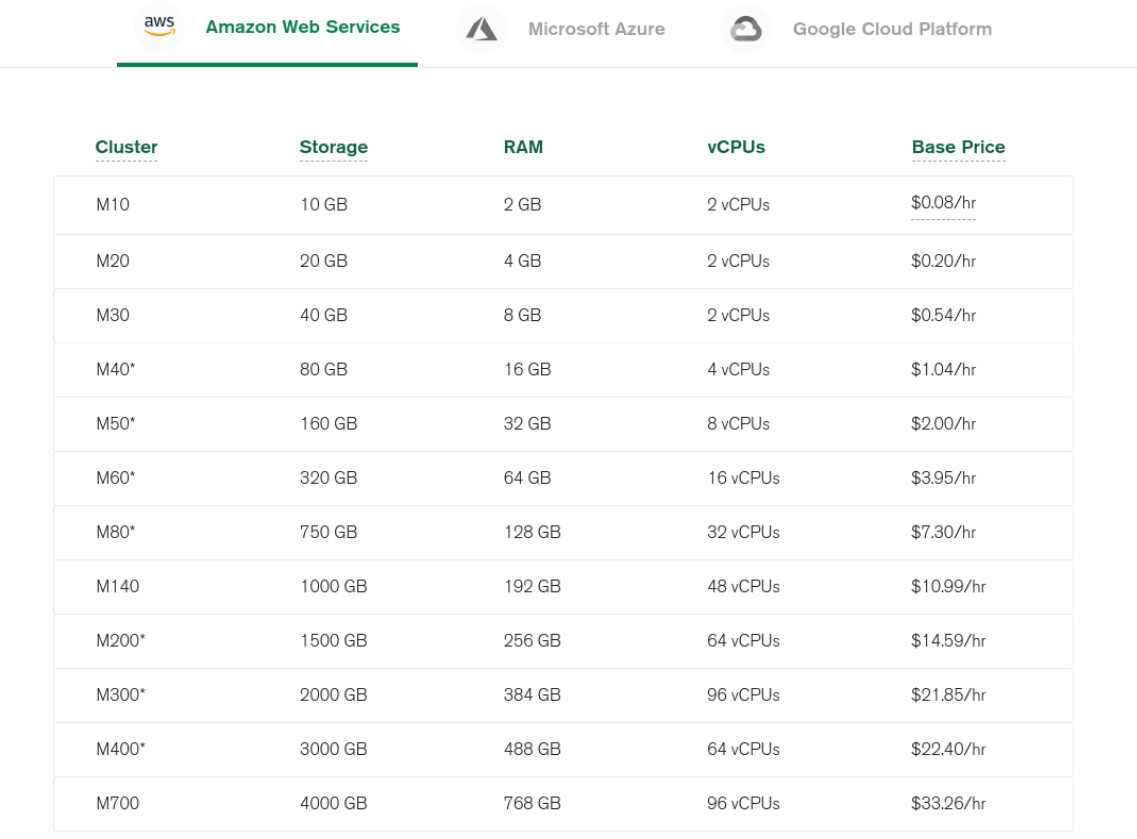 При возрастании нагрузки на сервер увеличивается объем оперативной памяти, CPU и т.п. Таким образом, по мере увеличения нагрузки появляется потребность в подключении дополнительных мощностей и происходит переход на следующий тарифный план (M10, M20, т. д.), а также подключаются дополнительные серверы -горизонтальное и вертикальное маштабирование.
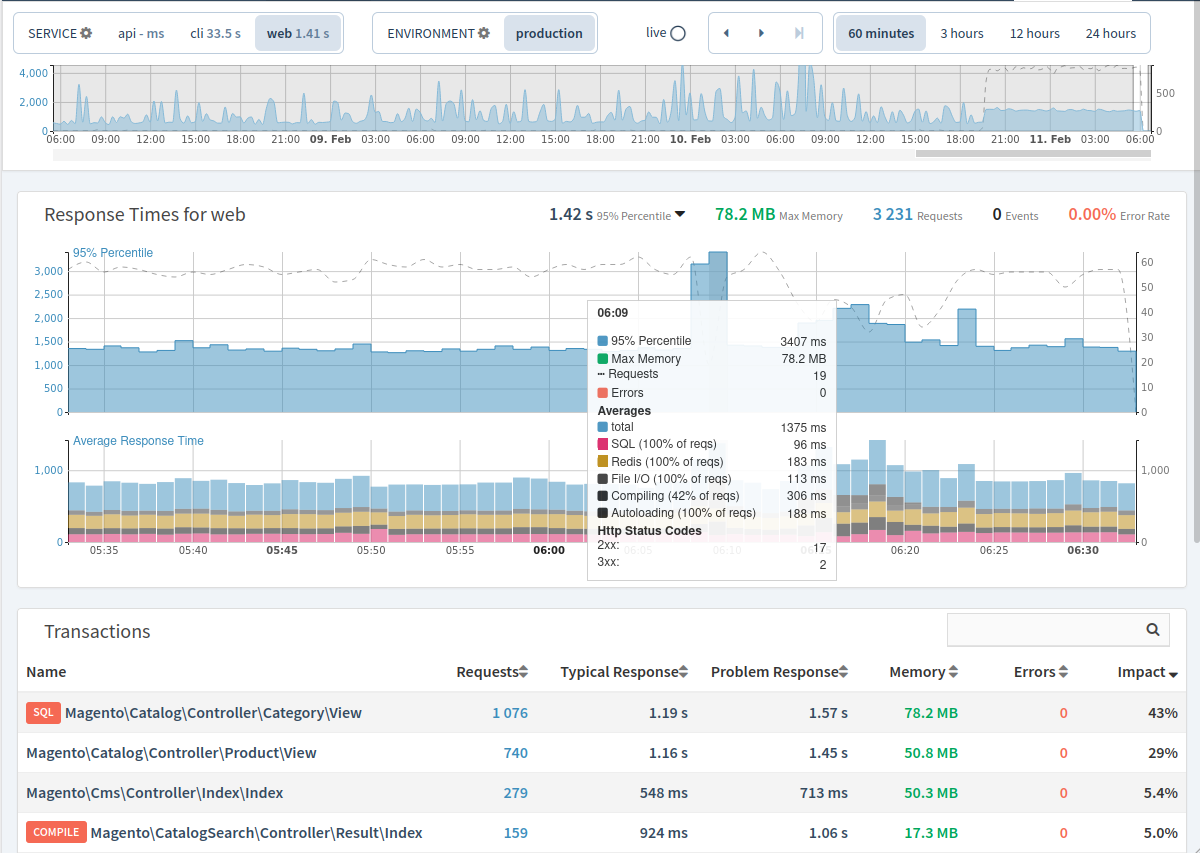
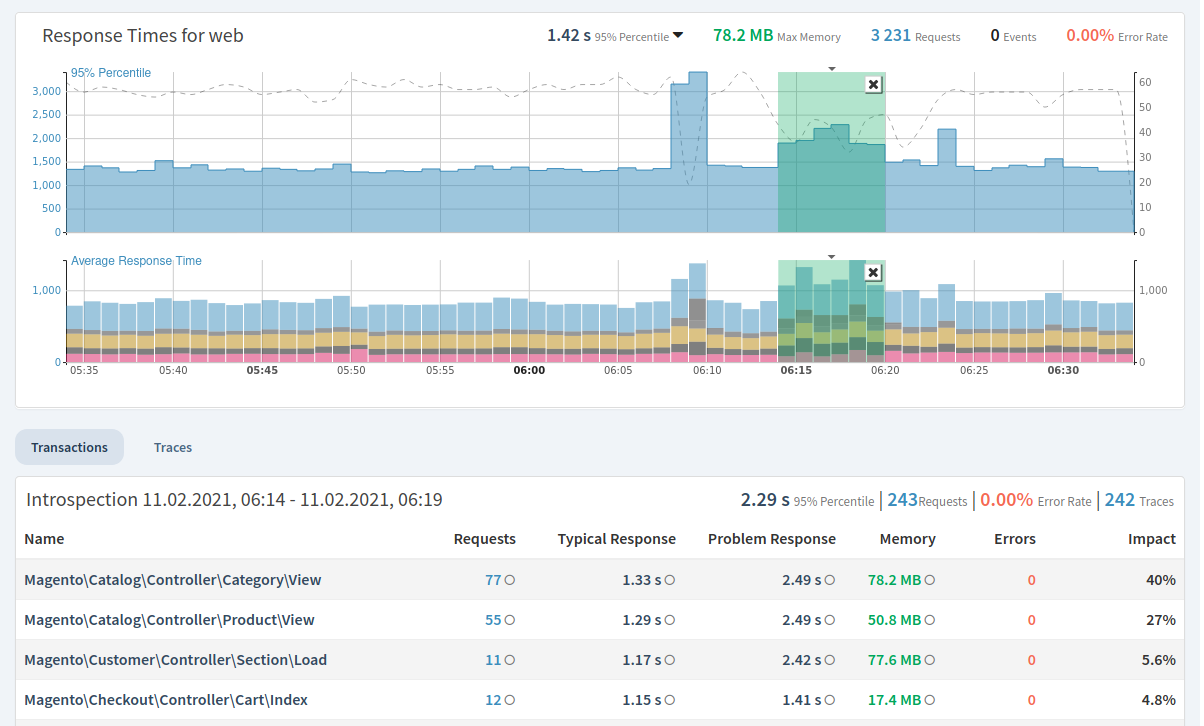
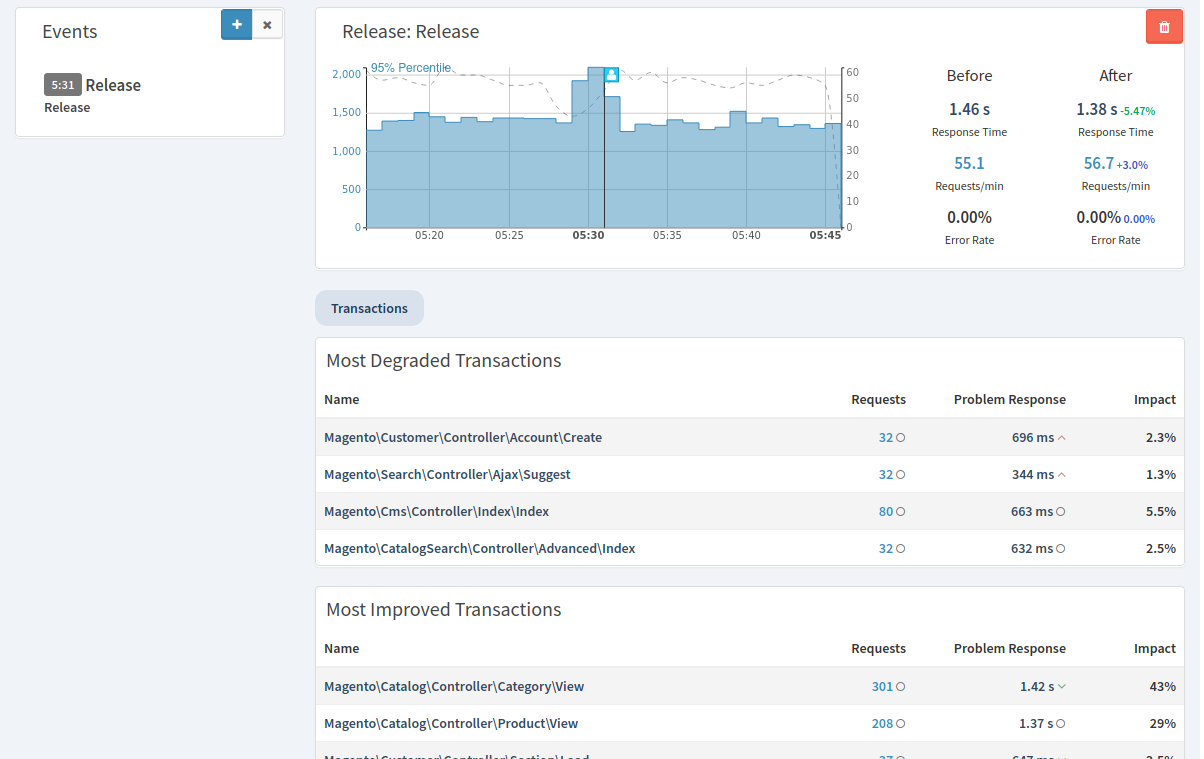
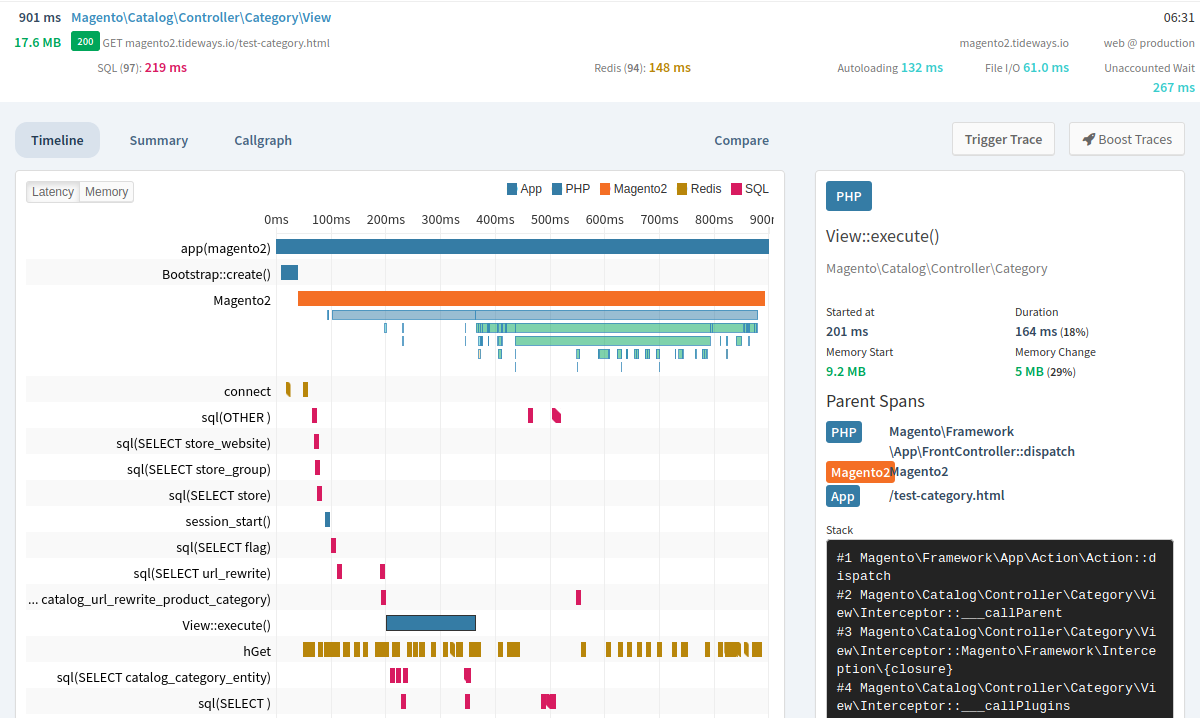
При возрастании нагрузки на сервер увеличивается объем оперативной памяти, CPU и т.п. Таким образом, по мере увеличения нагрузки появляется потребность в подключении дополнительных мощностей и происходит переход на следующий тарифный план (M10, M20, т. д.), а также подключаются дополнительные серверы -горизонтальное и вертикальное маштабирование. Взяты с официального сайта Grafana.com
Взяты с официального сайта Grafana.com