Почему ИТ-специалисты не желают разбираться с вопросами бухгалтерского учета и налогами
В борьбе за приверженность лучших специалистов современная ИТ-индустрия предлагает все новые и новые «плюшки». Одна из стандартных, must have «плюшек», бухгалтерское сопровождение ФЛП. Это одна из основных причин, почему ИТ-специалисты не желают разбираться с вопросами бухгалтерского учета и налогами ФЛП. Известны случаи, когда отсутствие бухгалтерского сопровождения заставляли кандидатов отказываться от оферы.
Другая распространенная причина: все мы слышали истории знакомых и друзей, что бухгалтерский учет занимает много времени и требует личного визита в государственные учреждения.
Несколько лет назад все было именно так. ФЛП или бухгалтеру нужно было лично идти в налоговую инспекцию. При этом уходило немало усилий, чтобы проснуться рано утром, постоять в пробках, затем выстоять очередь в кабинет специалиста, лично общаться с госслужащими и не всегда понимать, что именно им нужно от вас. Причем, если вам удалось решить вопрос с первого раза, это был успех. Обычно все действия нужно было повторять неоднократно.
Сейчас есть возможность решать онлайн почти 90% вопросов, связанных с ФЛП-деятельностью. Все стало намного быстрее и удобнее. Онлайн возможно: открыть/закрыть ФЛП, изменить систему налогообложения (изменить группу), добавить новые КВЭДы, подать квартальные отчеты, оформить декретный отпуск для ФЛП и т.д. В эпоху информационных технологий Украина взяла курс на цифровизацию всех государственных услуг – это касается и бухгалтерского учета ФЛП. Появилось много удобных государственных сервисов, таких как:
- Дия;
- Кабинет налогоплательщиков ;
- Государственный реестр физических лиц-предпринимателей (минюст) ;
- Опендатабот и т.д.
Финансовый учет ФЛП и налоги – это сложно и скучно. Это еще одна причина, почему ИТ-специалисты не интересуются вопросами ведения ФЛП. На самом деле, ведение учета финансов и подача отчетов происходит довольно просто. Вам необходимо разобраться и понять:
- что такое ФЛП;
- каковы основные пункты финансового учета ФЛП;
- какие есть налоговые особенности (что такое упрощенная система налогообложения, ЕСВ и единый налог);
- как выполнять требования законодательства и отслеживать изменения.
Более подробно обо всем этом будет немного позже.
Какие последствия для ФЛП, если отдать бухгалтерский учет на аутсорс
Accounting support – это дополнительные расходы, и поэтому в некоторых IT-компаниях эта опция может отсутствовать. В таких случаях IT-специалисту нужно самостоятельно вести ФЛП или делегировать их бухгалтеру на аутсорс (услуги фриланса-бухгалтера обычно оплачиваются за собственные средства). Но следует помнить, что за неправильные действия ответственность несет предприниматель, а не бухгалтер.
Самый главный риск в деятельности ФЛП – это ответственность всем своим имуществом. Если у Вас как у ФЛП есть долги перед государством или перед партнерами, возникает риск, что ваше имущество арестуют или заберут в судебном порядке. Наличие долгов может привести к аресту счетов и запрету выезда за границу.
Я рекомендую каждому IT-специалисту хотя бы поверхностно разобраться в особенностях системы налогообложения ФЛП, чтобы быть уверенным, что бухгалтер работает корректно.
Не мешает время от времени проверять деятельность своего бухгалтера. Вы должны знать, на какой системе налогообложения ваш ФЛП, понимать, почему именно эта группа ФЛП, каковы ее особенности, какие ставки налога на вашей группе. Также вы должны знать о существовании кабинета налогоплательщиков (это электронный кабинет налоговой), как туда зайти; знать о существовании состояния расчетов с бюджетом , где вы можете просмотреть, в каком объеме и в срок ли уплаченные налоги или своевременно увидеть, что вашему ФЛП начислен штраф/пеня/недоимка.
Какие еще последствия могут быть для предпринимателя, если не следить за ведением ФЛП? Рассмотрим самые типичные проблемы и как их можно избежать.
Ситуации бывают разные и все кейсы не прописать. Поэтому, независимо от того, ведет ли свой ФЛП самостоятельно или делегировал это штатному бухгалтеру или на аутсорс/фриланс, предприниматель обязан знать базовые понятия о ФЛП.
Какие базовые понятия о ФЛП должен знать каждый IT-специалист и сложно ли вести свой ФЛП самостоятельно
Физическое лицо-предприниматель (ФЛП) – это самая простая организационно-правовая форма субъекта хозяйственной деятельности. Если совсем просто — это физическое лицо, зарегистрированное как предприниматель.
Как вести бухгалтерский учет? Чтобы эффективно управлять финансами, нужно разобраться со следующими пунктами финансового учета ФЛП:
- учет доходов и расходов;
- оформление первичных документов;
- налогообложение;
- сроки сдачи отчетности и уплаты налогов.
Далее расскажем все на примере ФЛП третьей группы, являющейся самой распространенной среди ИТ-специалистов благодаря ее упрощенной системе налогообложения и возможности предоставлять услуги не единиками (в том числе иностранным компаниям).
Учет доходов и расходов
Ведение учета доходов является обязательным для ФЛП. С 2021 года в Украине отменена регистрация книги учета доходов и расходов в налоговой. Теперь ФЛП могут вести бухгалтерский учет в произвольной форме (например, вести таблицу в excel или в традиционном формате бумажной книги/блокнота и т.п.).
Если вы решили перейти на электронную таблицу, то не спешите избавляться от книги учета доходов. Сначала необходимо подать заявление об отмене его регистрации и затем хранить книгу в течение 3-х лет с момента окончания отчетного периода, в котором была сделана последняя запись.
Главное условие ведения учета доходов: в свободном реестре нужно показать свои месячные обороты, соответствующие первичным документам.
Оформление первичных документов
Что такое первичные документы? ФЛП, предоставляющий услуги и получающий оплату в безналичной форме, должен иметь следующие документы:
- банковскую выписку;
- договор с компанией, которой вы предоставляете услуги как ФЛП, подписанный двумя сторонами;
- счет-фактуру за выполненные работы (этот документ еще называют инвойс).
Первичные документы должны быть связаны с каждым контрагентом. Их следует хранить в течение трех лет на случай налоговой проверки. Если контролирующие органы не увидят первичные документы о происхождении средств, это может стать основанием для перехода на общую систему «задним» числом.
Налогообложение
Упрощенная система налогообложения – одно из основных преимуществ избрания ФЛП третьей группы. На упрощенной системе налогообложения следует платить единый налог и ЕСВ.
Единый налог – это налог, уплачиваемый субъектами хозяйственной деятельности на упрощенной системе налогообложения. Для ИТ-специалиста обычно это 5% от дохода, при условии, что предприниматель не платит НДС.
Единый социальный взнос (ЕСВ) – это консолидированный страховой взнос в Украине, сбор которого осуществляется в обязательном порядке и на регулярной основе. ЕСВ дает право предпринимателю на получение больничных, декретных выплат и соцпомощи, а также государственной пенсии. ЕСВ – это налог с фиксированной суммой, 22% от минимальной заработной платы.
Сроки сдачи отчетности и уплаты налогов
| ФЛП 3-й группы | Периодичность | Сроки сдачи отчетности и уплаты налогов |
| ЕСВ-налог | платит ежеквартально | к 20-му числу месяца следующего за кварталом |
| Налоговая декларация | подает ежеквартально | в течение 40 календарных дней после окончания отчетного квартала |
| Единый налог | платит ежеквартально | в течение 50 календарных дней после окончания отчетного квартала |
Оплачивать налоги и подавать отчеты можно онлайн в личном кабинете налогоплательщика – это бесплатно. Предпринимателям следует соблюдать сроки уплаты налогов и предоставление отчетов во избежание штрафов.
| ФЛП 3-й группы – ключевые моменты | |
| Лимит дохода в год
(с 01.01.2022 по 31.12.2022) |
7 млн. 585,5 тыс. грн. |
| Единый налог (ЕП) | 5% от дохода для неплательщиков НДС
3% от дохода для плательщиков НДС |
| ЕСВ | С 1 января 2022 г. уплата ЕСВ = 1430,0 грн./мес
4290 грн за 1-3 квартал 2022 года С 1 октября 2022 г. уплата ЕСВ = 1474,0 грн./мес 4422 грн за 4 квартал 2022 года |
| Контрагенты и клиенты | На ФЛП-счет ФЛП можно получать от:
– обычного физлица; – плательщики единого налога; – ФЛП и юрлица на общей системе; – иностранных компаний и физлиц. Получать доход можно в гривне и валюте. |
| Виды деятельности | Все виды деятельности, кроме 291.5 НКУ |
| КВЭДы для ИТ-специалистов | 58.21 Издание компьютерных игр
58.29 Издание другого программного обеспечения 62.01 Компьютерное программирование 62.02 Консультирование по вопросам информатизации 62.09 Другая деятельность в сфере информационных технологий и компьютерных систем 63.11 Обработка данных, размещение информации на веб-узлах 63.12 Веб-порталы 63.99 Предоставление других информационных услуг 70.22 Консультирование по вопросам коммерческой деятельности и управления 74.10 Специализированная деятельность по дизайну |
Кроме своевременной уплаты налогов и предоставления отчетности, ФЛП должен следить за объемом годового заработка (предел дохода на год). Если вы превысили лимит, необходимо перейти на общую систему налогообложения с 1 числа следующего за отчетным кварталом месяца и уплатить 15% ЕН от суммы превышения. Или налоговая сделает это за вас и исключит ваш ФЛП из реестра плательщиков единого налога. Возвратиться на упрощенную систему налогообложения можно будет только со следующего календарного года.
Обратите внимание! Мало кто знает, что после закрытия ФЛП повторно открыть ФЛП на упрощенной системе можно будет только с началом следующего календарного года — то есть с 1 января следующего года. Бывали случаи, когда по опрометчивости специалисты закрывали свой ФЛП в начале года и затем сталкивались с проблемой повторного открытия ФЛП.
Итак, в ведении ФЛП нет ничего тяжелого. Разобравшись во всех нюансах, каждый может заниматься этим самостоятельно.
Какие инструменты необходимы для самостоятельного ведения ФЛП
| Название | Описание |
| Ключ КЭП
(квалифицированная электронная подпись) |
КЭП обеспечивает целостность документов и идентифицирует личность.
С помощью электронной подписи можно подписывать электронные документы, регистрироваться на государственных порталах, пользоваться электронными услугами. Документы с этой подписью имеют такую же юридическую силу, как и документы, подписанные собственноручно. Получить ключ КЭП можно как офлайн, так и онлайн. Если вы клиент ПриватБанка – то можете бесплатно сгенерировать ключ КЭП через личный кабинет. Также можно получить электронную подпись от “Дия”. |
| Сервис Действие | позволяет удаленно зарегистрировать или закрыть ФЛП, внести изменения (добавить новый КВЭД). |
| Реестр плательщиков единого налога | Это государственный сайт , который поможет проверить, находится ли ваш ФЛП в Реестре плательщиков единого налога (т.е. на упрощенной системе налогообложения).
Вы можете сделать бесплатный запрос – для этого нужно ввести только ваш Налоговый номер (указывать ФИО не нужно) и нажать кнопку [поиск]. Обязательно обращайте внимание на поле «Дата исключения из реестра» — если напротив этого поля есть дата — ваш ФЛП уже находится на общей системе налогообложения. Общая система означает, что теперь вы должны платить налог 18% НДФЛ + 1,5% военный сбор + ЕСВ 22% чистого дохода, вместо 5% единого налога. Также другая система отчетности и другие сроки уплаты налогов. Рекомендуем регулярно проверять, что ваш ФЛП находится в Реестре плательщиков единого налога, чтобы избежать неприятных сюрпризов. |
| Электронный кабинет налогоплательщиков | Позволяет отдаленно сдать отчеты и пересмотреть предыдущую отчетность, проверить наличие долгов, своевременность принятия отчетов и вести переписку с налоговой службой.
Особое внимание обращайте на начисление долговых обязательств и своевременность принятия отчетов. |
| Учет доходов ФЛП | Электронная таблица. |






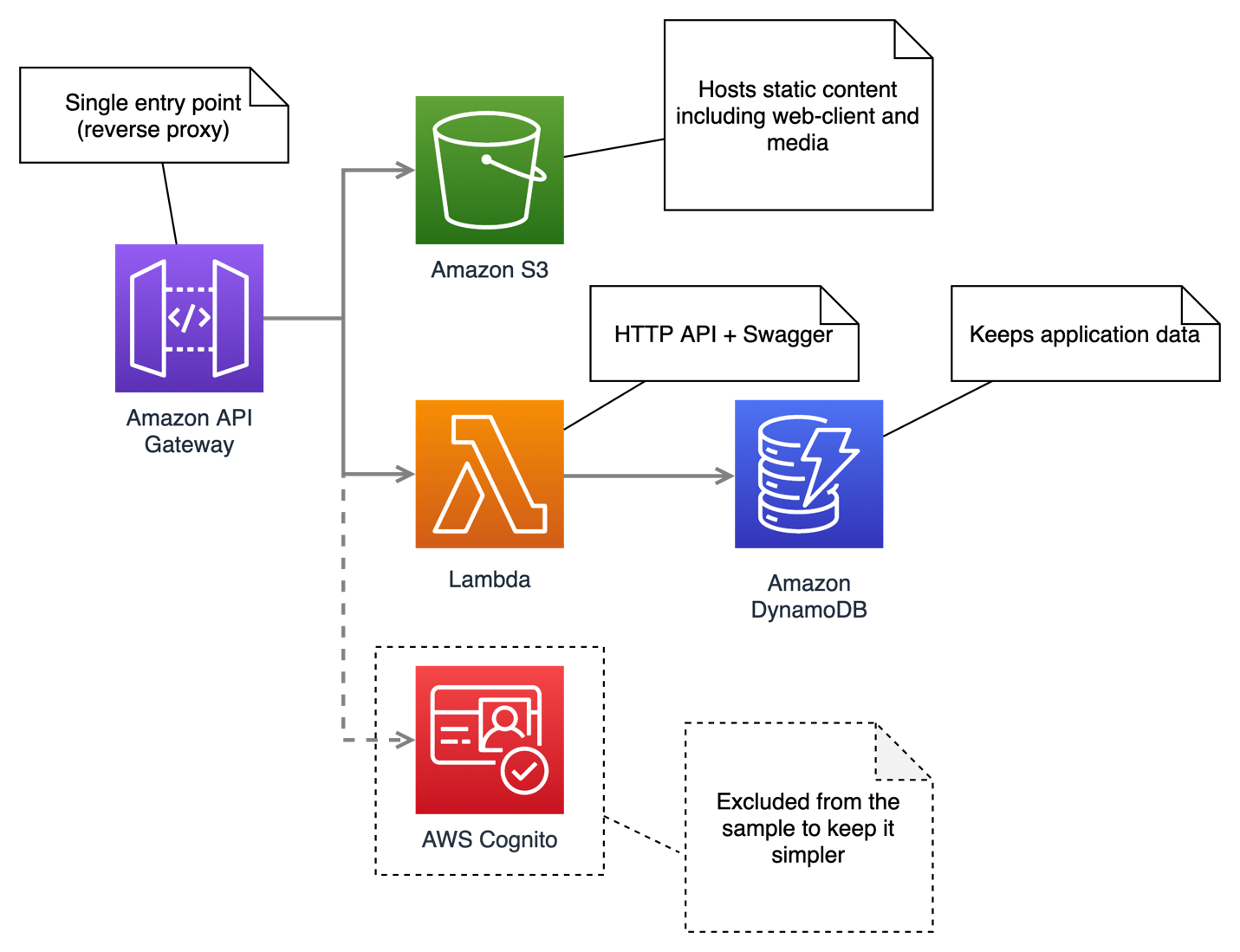
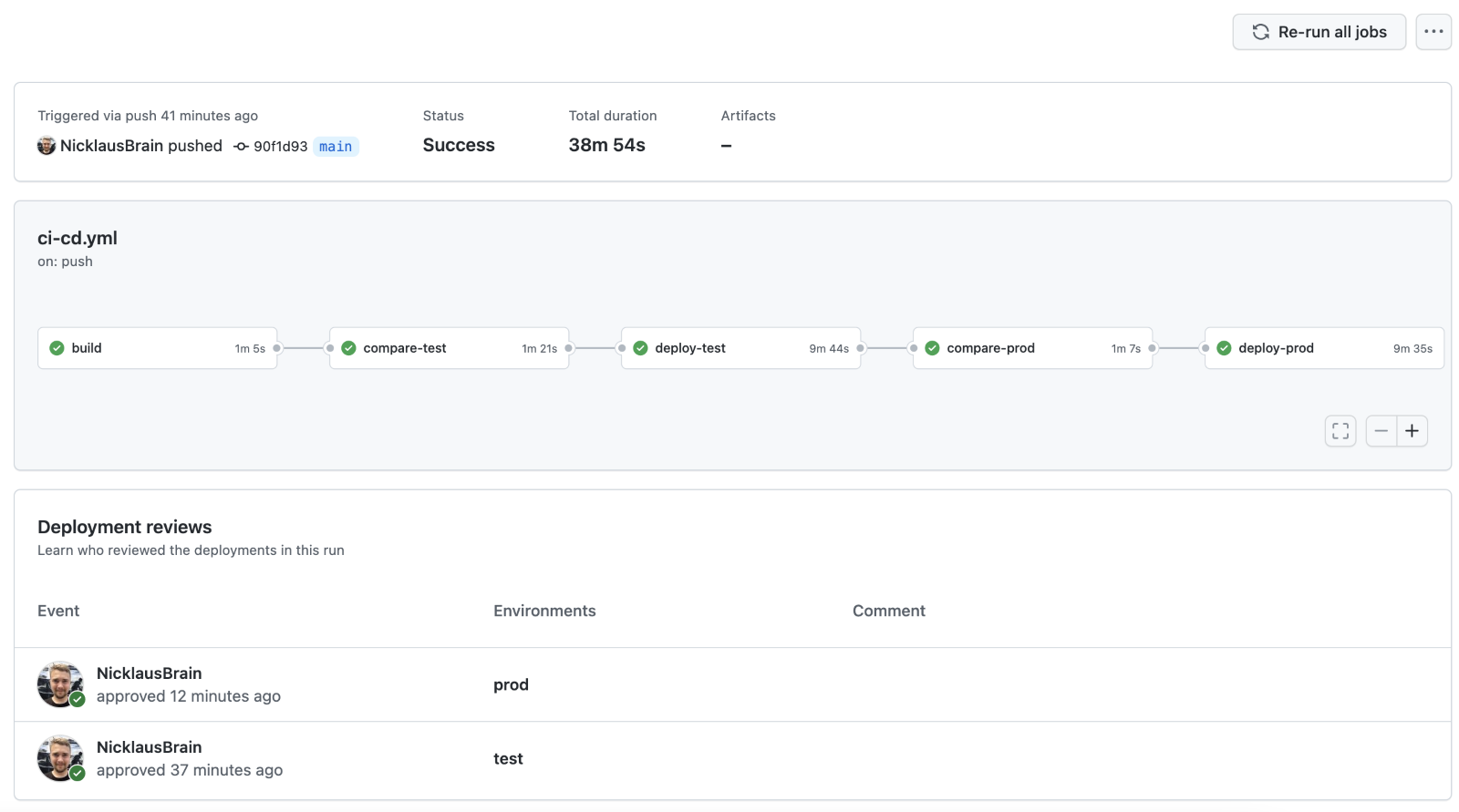 Изображение 3. Результат доставки GitHub Workflow
Изображение 3. Результат доставки GitHub Workflow

