Мережеві технології є базовою навичкою для кожного інженера-програміста. Щоб по-справжньому зрозуміти, навіщо існують мережеві концепції та які реальні проблеми вони вирішують, корисно розглядати їх у дії, а не в ізоляції.
У цій статті ми простежимо розвиток вигаданої платформи бронювання подорожей TravelBody. У міру того як застосунок еволюціонує від одного сервера до складної хмарної системи, ми розбиратимемо кожну мережеву концепцію саме тоді, коли вона стає необхідною.
Від одного сервера до інтернету
Коли TravelBody лише запускався, увесь застосунок працював на одному сервері. Така архітектура була простою, але одразу виникло важливе питання: як користувачі знаходять сервер в інтернеті?
IP-адреси: ідентифікація пристроїв у мережі
Кожному пристрою, підключеному до мережі, потрібен унікальний ідентифікатор, щоб інші пристрої знали, куди надсилати дані. Цей ідентифікатор називається IP-адресою. Вона працює так само, як поштова адреса будинку: без неї доставка даних неможлива.
Сервер TravelBody отримав публічну IP-адресу, завдяки чому будь-який пристрій в інтернеті може надсилати запити безпосередньо на цей сервер.
DNS: зручні для людей імена
Запам’ятовувати IP-адреси незручно, тому використовується DNS (Domain Name System). DNS перетворює легко запам’ятовувані доменні імена на IP-адреси.
Коли користувач вводить travelbody.com у браузері, DNS автоматично знаходить відповідну IP-адресу та під’єднує користувача до потрібного сервера. Це схоже на вибір контакту за ім’ям у телефоні замість набору повного номера.
Кілька застосунків на одному сервері
Зі зростанням TravelBody на одному сервері почали працювати одразу кілька компонентів:
-
користувацький вебсайт
-
база даних з інформацією про бронювання
-
сервіс обробки платежів
Усі вони використовували одну й ту саму IP-адресу, що створило нову проблему.
Порти: спрямування трафіку до потрібного застосунку
Цю проблему вирішують порти. Порти — це пронумеровані канали зв’язку на сервері, від 1 до 65 535. Кожен застосунок «слухає» свій порт.
Наприклад:
-
вебзастосунок: порт 80 (HTTP) або 443 (HTTPS)
-
база даних MySQL: порт 3306
-
платіжний сервіс: порт 9090
Коли запит надходить на сервер, номер порту вказує операційній системі, якому застосунку його передати. IP-адреса — це адреса будівлі, а порти — номери квартир усередині неї.
Підвищення безпеки за допомогою сегментації мережі
Зберігання платіжних даних і персональної інформації на одному сервері створювало серйозні ризики безпеки. У разі зламу зловмисник отримував би доступ до всього одразу.
Підмережі: поділ мережі
Для зменшення ризиків було впроваджено мережеву сегментацію з використанням підмереж. Підмережі ділять мережу на ізольовані зони з різним призначенням:
-
публічна підмережа для фронтенд-серверів
-
приватна підмережа для серверів застосунків
-
окрема підмережа для баз даних
Такий поділ обмежує доступ і зменшує наслідки можливих атак.
Маршрутизація: з’єднання сегментів
Коли з’являються підмережі, їх потрібно з’єднувати. Маршрутизація визначає, як дані переміщуються між сегментами мережі — подібно до GPS, який прокладає маршрут з точки А в точку Б.
Контроль трафіку за допомогою міжмережевих екранів
Те, що мережі можуть обмінюватися даними, не означає, що їм слід робити це без обмежень. Тут на сцену виходять міжмережеві екрани (firewalls).
Firewalls: застосування правил безпеки
Міжмережевий екран перевіряє мережевий трафік і дозволяє або блокує його відповідно до заданих правил.
Існує два основні типи:
-
host-firewalls, які захищають окремі сервери
-
network-firewalls, які фільтрують трафік між підмережами
Наприклад:
-
сервер бази даних приймає з’єднання лише на порт 3306 і лише з підмережі застосунків
-
фронтенд-підмережа приймає вхідний інтернет-трафік лише на портах 80 і 443
Багаторівневий захист означає, що зловмиснику доведеться пройти кілька рівнів безпеки, щоб завдати шкоди.
Приватні мережі та доступ до інтернету
Зі зростанням TravelBody з’явилися десятки бекенд-серверів, що працюють у приватних підмережах. Ці сервери використовують приватні IP-адреси, які недоступні напряму з інтернету.
NAT: безпечний вихід в інтернет
Водночас приватним серверам усе одно потрібен доступ до інтернету, наприклад для:
-
завантаження оновлень
-
звернення до зовнішніх API
Цю задачу вирішує NAT (Network Address Translation). NAT дозволяє кільком серверам із приватними IP-адресами використовувати одну публічну IP-адресу для вихідних з’єднань.
Процес виглядає так:
-
сервер надсилає запит на NAT-пристрій
-
NAT замінює приватну IP-адресу на публічну
-
відповідь з інтернету повертається потрібному серверу
Таким чином сервери залишаються прихованими, але мають доступ до зовнішніх ресурсів.
Перехід у хмару
Керування фізичними серверами стало дорогим і повільним, тому TravelBody перейшов у хмару, орендуючи обчислювальні ресурси замість володіння обладнанням.
Мережеві принципи залишаються незмінними
Хоча інфраструктура змінилася, мережеві основи залишилися тими самими:
-
IP-адреси
-
порти
-
підмережі
-
маршрутизація
-
firewalls
-
NAT
У хмарі ці елементи надаються як керовані сервіси.
Virtual Private Cloud (VPC)
VPC — це ізольована частина мережі хмарного провайдера. Це схоже на оренду власного поверху у великій офісній будівлі. Усередині VPC TravelBody відтворив знайому архітектуру з публічними та приватними підмережами, таблицями маршрутизації, інтернет-шлюзами та NAT-шлюзами.
Контейнери та переносимість застосунків
Під час переходу до мікросервісної архітектури складність розгортання різко зросла. Відмінності між середовищами розробки та продакшену почали спричиняти помилки.
Контейнери: пакування застосунків
Контейнери пакують усе необхідне для роботи застосунку — код, середовище виконання, бібліотеки та налаштування — в один переносимий об’єкт. Це гарантує однакову поведінку застосунку в різних середовищах.
Для контейнеризації сервісів TravelBody використовувався Docker.
Мережеве взаємодіяння контейнерів
Контейнери взаємодіють через:
-
bridge-мережі для зв’язку на одному сервері
-
проброс портів, який дозволяє отримувати доступ до контейнерів ззовні
-
overlay-мережі, що об’єднують контейнери на різних серверах в одну віртуальну мережу
Ці механізми по суті повторюють знайомі мережеві концепції, такі як NAT і маршрутизація.
Kubernetes: керування контейнерами в масштабі
Коли TravelBody почав запускати сотні контейнерів на десятках серверів, ручне керування стало неможливим.
Поди та IP-адреси
У Kubernetes контейнери запускаються всередині подів. Кожен под отримує власну IP-адресу, спільну для всіх контейнерів усередині нього.
Однак поди є тимчасовими: вони можуть видалятися, пересоздаватися й переміщуватися, а їхні IP-адреси змінюються.
Сервіси: стабільна мережа для динамічних подів
Цю проблему вирішують Kubernetes-сервіси. Сервіс надає:
-
постійну IP-адресу
-
стабільне DNS-ім’я
Сервіс автоматично спрямовує трафік до працездатних подів, навіть якщо вони пересоздаються. Застосунки підключаються до сервісу, а не до конкретного поду.
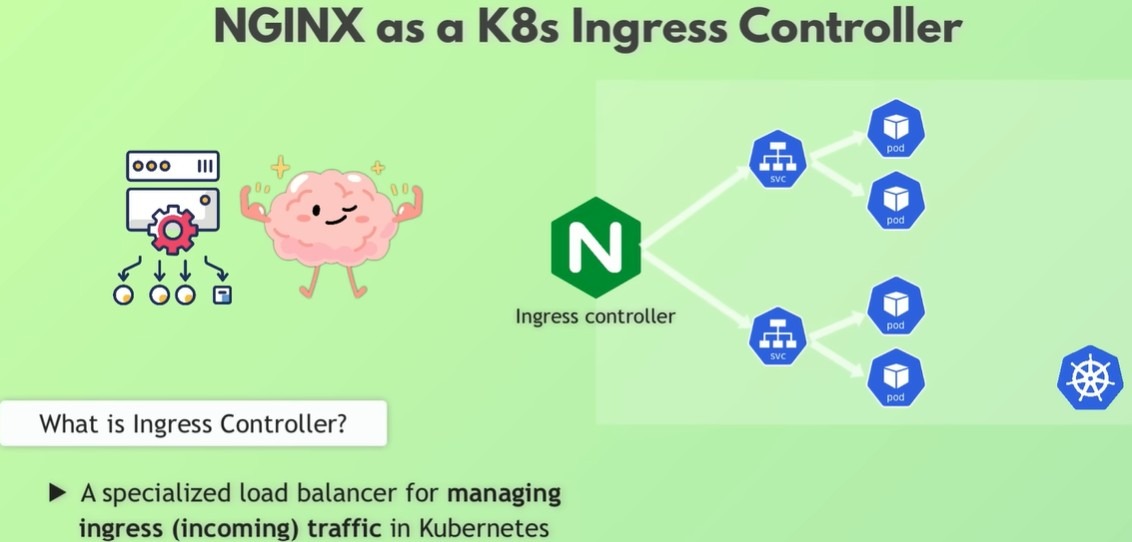
Публікація застосунків за допомогою Ingress
Щоб зробити сервіси доступними з інтернету, в Kubernetes використовується Ingress.
Ingress виступає єдиною точкою входу, розподіляючи вхідні запити між сервісами на основі доменів або шляхів URL.
Наприклад:
-
запити до
travelbody.comспрямовуються до вебсервісу -
API-запити — до сервісів бронювання або платежів
Ключові мережеві основи: підсумок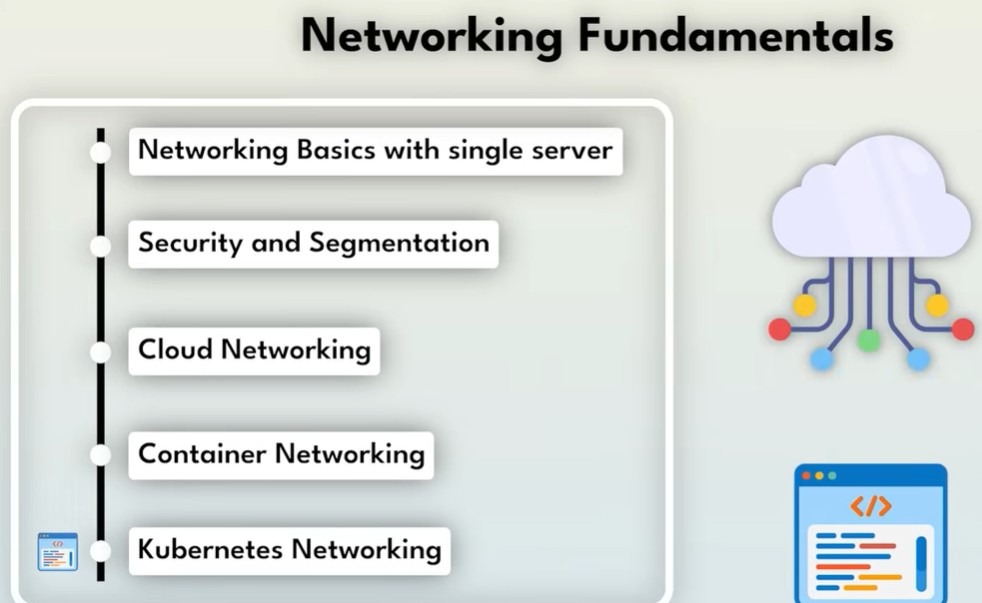
Простеживши шлях TravelBody, ми виділили п’ять фундаментальних мережевих концепцій:
-
IP-адреси та DNS — ідентифікація пристроїв і перетворення імен
-
Порти — спрямування трафіку до потрібного застосунку
-
Підмережі та маршрутизація — організація мережі та з’єднання сегментів
-
Firewalls — контроль і захист мережевого трафіку
-
NAT — безпечний доступ приватних систем до інтернету
Ці принципи працюють усюди: на фізичних серверах, у хмарі, в контейнерах і в Kubernetes. Інструменти змінюються, але основи залишаються незмінними.
Опанувавши ці фундаментальні концепції, інженер зможе розуміти, проєктувати та ефективно усувати проблеми в системах будь-якого масштабу.